August 24, 2020 Career, Personal, Success 4 comments
Goodbye Amazon; Hey Google
Disclaimer: opinions in this post are my own and do not represent opinions of my current employer or any of my past employers or any of my or their clients.
Time for some big news: as of 24th of August I’m a Googler or rather a Noogler, as newly joined employees are being called.


It has been almost a month since I left Amazon. Here is a “mandatory” badge photo. Amazon was a place of rapid learning on multiple fronts, not just from engineering perspective but from many other. I learned Java or at least enough so that I can write code in it (not that is is much different from C#, which I knew before) and I learned how scalable and resilient solutions are built. But other than that and most of what I learned wasn’t programming related but more of understanding on how truly data-driven, customer-oriented (or let’s say “customer obsessed”) company is run. Seeing this machinery crunching from inside was absolutely astonishing. Probably what’s the most prominent about working for Amazon is its strong prevalent culture embodied in 14 Leadership Principles. Each and every aspect of work is guided by those principles. It starts with your interview to be an Amazonian. It takes you through working days, your promotion, decision making and anything you could think of. People live by these principles.
During 2.5 years I worked on retail project to launch and scale a fulfillment channel in one of the rapidly growing markets. The time allowed me to meet and work with amazing and smart people. The team I was on was awesome and my manager was a boss you can only dream about. I liked the vibe of Vancouver’s office, maybe because it was much more multi-cultural and diverse compared to Seattle (though I might be mistaken). I was promoted at Amazon to SDE3. The project I was on was and probably is gaining more and more of momentum.
Some of you would be curious why I left Amazon if things were going so well. (Just look at AMZN stock price for one data-point). As every job there are negative aspects. Amazon is somewhat notorious for those, but I didn’t leave Amazon to leave Amazon. I am not excluding joining Amazon again some years from now. Current decision is more to learn about another big company, its culture and processes, especially when we are talking about Google.
I don’t know what exactly to expect from this change. Many software engineers see Google as the most desirable employer to join. The company is famous for its high engineering standards, googley culture and so many other things. I’m excited to the core to embrace what is coming at me.
Among 24 checkboxes in my 2020 plan working for Google will tick few of them. This includes double-tick on meaningful work-related change, learning a new programming language (will be coding in Go and Python), and unexpectedly might change my coffee and sleeping habits (if I succeed in regularly getting up before 6AM and not having coffee :) ).
What made me get into blogging?
April 19, 2020 Blog No comments
Recently a person on LinkedIn asked me this: “What made you get into blogging?“
This is not the first time I get this question. In most situations this would come from a coworker who saw my blog for the first time or it would come from someone on internet seeking advice.
The answer
I wrote my first blog post in October 2009. In the post I am talking about career aspirations, being pragmatic (though I probably meant ambitions) and about the intent of the blog to post technical findings in order to help people online. English is unbearable, but the post is ending with “I hope this will help you and me!” And it helped.
So far I have 317 posts and some 717 comments. I’ve got many “Thank you” comments for the things people were able to find on the blog helping them solve their problems. Some people know me because of this blog. Some have greater trust in me because of this blog, some are inspired by this little work of mine. Most of all, it always helped me get more contacts, including those by recruiters. I won’t have numbers, because people don’t always say “hey, I contacted you because I saw your blog and thought you can be a good fit for our team”, though this happens at times as well. Long story short, the blog was and is extremely beneficial to me.
So what made me write here in the first place? I think there were few factors. Blogging was very popular back in 2009 and many others were also writing. If you remember those times, everyone had Google Reader and was starting their day with going through recent posts. Though, the main factor that made me write was probably inspiration by Derik Whittaker with whom I had a chance to work. He was Microsoft MVP at that time (probably now as well) and was having huge influence over development teams he was dealing with.
Encouragement
I think inspiration and mentorship are things that help people who are just starting in their careers. Therefore I would encourage anyone who is reading this to start writing. It doesn’t have to be a public blog (though I would recommend). It can be internal company blog, it can be answers on SO, it can be great documentation at work, it can be a book you always wanted to start writing, it can be scientific publication. Really anything that you feel you are close to and where you feel comfortable starting. There are numerous benefits of writing, like building your brand, improving communication skills, organizing thoughts, learning through teaching. Let me bring one quote from a book I read not too long ago:
The act of writing is a good example of metacognition because when we think about composing sentences and paragraphs, we’re often asking ourselves crucial metacognitive questions: Who will be reading this? Will they understand me? What things do I need to explain? This is why writing is often such an effective way to organize one’s thoughts. It forces us to evaluate our arguments and think about ideas.
Learn better by Ulrich Boser
Another question
So that was the answer to the question on why I started blogging and what are some of the benefits of doing so. Here is a more important follow-up question to ask: “What made me stick to blogging?” And answer is – you! All the people who read this blog or who have read it in the past, those who comment, those who ask questions, those with whom I work or worked in the past. If not for these little inspirations from each one of you this blog would not exist for all these 11 years. Thank you!
Becoming Senior Software Engineer and Career Path
April 4, 2020 Career, Success 14 comments
Disclaimer: opinions in this post are my own and do not represent opinions of my current employer or any of my past employers or any of my or their clients.

Señor Engineer
I just had to put this picture for few friends of mine ;)
Recently I got promoted to Senior Software Engineer position at Amazon. This post starts with my career story leading to the place where I am now and finishing with thoughts on titles, their meaning, and further thoughts on professional growth for software engineers. Bear with me, this is a long post with no conclusion.
Career Path so Far
My first job was with a Ukrainian outsourcing company, Softserve Inc. I started there in April 2008 and left the company in December 2011 to pursue new experiences in Western Europe. During those 3.5 years I got promoted twice. When exiting the company I was titled “Senior Software Developer” leading a team of 8 developers. Most of us were young software engineers just some years out of college, we were in a different kind of business than all of my next jobs (outsourcing vs. product).
My first job is still an inspiration on how I should be approaching my career. Being career driven, ambitious, and overly eager to learn non-stop were the main characteristics of me back then. I was brave enough to speak at user group events, and teach others. I’ve just read old post on leaving my first job and it inspires me. My English is horrible, but the meaning is everything:
I joined my second company in Austria as a Software Engineer (intermediate level) and was extremely happy with the quality of software we were producing and everyone’s skills. This was the first time I started learning about distributed systems and just loved working there. I hammered the keyboard non-stop and was happy. As it always is, every story has its end. I left my second company banally to earn more money. Sad but true. They tried to keep me by offering some XX% salary increase, and… drumbeat… a “Senior Software Engineer” title. I rejected. I don’t know if that was the right move, but that clearly was time when I chose money over title or even over happiness at work. Below is a blog post about leaving second job and reasons why I chose money, if you are interested:
I spent only 1.5 years with second company after which I had long 4.5 years with United Nations (well, the IAEA, which is international organization associated to UN). I started as a contractor Software Engineer – my title didn’t really matter as at first I was self-employed, I could probably have called myself “God Of Software Engineering” at “Greatest Software Company In The World” and it would not matter as for the IAEA I was just a contractor and they made me go through airport-like security each and every day for few years. In the end they hired me as a Staff Member with a cryptic title “Systems Analyst / Programmer” putting me in charge of a team of contractors :). This was another bump in my income as suddenly I didn’t have to pay taxes (yes, let me repeat it – I legally did not have to pay any taxes at all).
The place is definitely unlike any other workplace. There were over 100 different nationals working in the same building with me. I worked directly with people from Iraq, Zimbabwe, Azerbaijan, UK, Australia, Canada, China, India, and so many other countries it was virtually impossible to know who is from where. There was so much learning about different cultures. This alone was awesome. There were tons of other benefits related to working at that place. Not everything was great. For instance, I had to come to work in a suite – yes, software engineer in a suite. More seriously I was looking for more growth. Even if I managed to get promoted that would not make any major difference. Maybe, I would just start wearing a tie in addition to suite. Unfortunately, I don’t have a blog post about leaving that place, even though I have so much to share. All I have is this picture of me getting out of a nuclear reactor and tweet:
There was a t-shirt swap. Thank you, IAEA friends, for the great years. I am officially Amazonian now. pic.twitter.com/KADEUuk6iW
— Andriy Buday (@andriybuday) January 26, 2018
Up until 2018 I was mostly .NET engineer with desktop, distributed, mobile and web skills. Starting to work for Amazon meant dropping good portion of that knowledge and learning Java and many things from the “dark side” (oh, sorry, that’s the other way around). I’ve joined Amazon as SDE2 and I didn’t mind joining on an intermediate title as I knew that working for one of FAANG sets me on a totally different growth path that brings challenges of a different magnitude. I cannot talk too much about work at Amazon other than what’s public. But it is not a secret that one line of code change could mean MM$ of loss or MM$ of revenue here just because of enormous scale. This is why Amazon always tries to raise the engineering bar. Amazon is a place of insane growth. Love it.
Do titles matter?
So where am I going with all of this? If you followed me so far, you would notice I always skipped titles either for new experience, more money, or growth opportunities.
So do titles matter? I think it depends on how you look at them. You can be “CTO” at company of 10 people making 100K a year, or be a fresh grad Junior Engineer at top company in bay area and make twice as much. But “CTO” might have a chance to grow her company to giant and make millions because she is in a different growth position. It is not only about titles but what they really mean, what level of responsibility they bring, what is the pay band, what impact, knowledge, and skills are expected. Most often companies define levels boiling down to some kind of seniority and scope of responsibilities and then would define different titles having technical track, management track and maybe few more.
Long story short, I think titles do matter but they matter in a context.
When I look at titles of people whom I knew from my first job I get humbled – some of them got promoted 6 times to the likes of “Vice President of Something” or “Senior Solutions Architect” or even something more pompous. Not all of them, though, some of them who were less ambitious or had different goals took different paths. This makes me wondering where I would have ended up had I stayed. I will never know, but should I even care? Should you care about your past decisions and think too much? We should not! Regret is a painful emotional state to avoid. We need to always try to minimize potential regret.
So how to get to the next level?
Everyone of us has a different path in life and in our careers and that is just the way it is. We care about ourselves, our families and people we know and relate to. So for the most part you don’t care about me or my title the same way as I don’t care about your title or other engineers’ titles. That having said, you might be interested in this post as you might be wondering how you can get to your next level or what you can learn. Human nature is not to be happy with what they have and I am ok with this. This is normal.
Here are original bullet points from me:
- Do your job and do it well. Really well. Master the tools. Balance delivery and long-term perspective.
- Never ever stop learning. Improve yourself in all areas. Soft and hard skills.
- Work on projects that have impact and could grow to something big. If you don’t think you are on such a project change the project or change the project.
- Find a mentor and work with your manager and others to get you where you want to be.
- Look at what next level implies and do those things. Take responsibilities. Now.
- Make your work visible and document what you’ve done.
- Stay healthy. Sleep well.
How much in a promotion is luck?
This is a difficult question. If I take philosophical approach I would say that a lot is due to luck – we just pop up like little candles in different parts of the world and then we fade away, you might have been unlucky to be born in poorest country in the world or your parents might have started preparing you for Stanford in elementary school. You might have worked on a project that suddenly started making millions of dollars growing and riding everyone’s careers with it or you might have worked on failed project and got laid off.
Another cold-blooded view is absolutely deterministic. You are worth exactly what you are worth, meaning that if you somehow think you deserve higher level this is simply wrong as you were not able to determine what it takes to get that what you want and therefore you don’t deserve it. Big companies have data-driven approach to promotions. If you have the data for the next level you will undeniably get it.
My overnight promotion was years in making.
Conclusion?
This was just a story. You can make your own conclusions. I’m just encouraging you not to give up. Feel free to leave me a congratulatory or any other kind of comment.
Among other things, this promotion completes one of the important parts of my 2020 new year resolution. I’m now 12.5% done and more is to come.
On Learning
February 17, 2020 Opinion 2 comments
If you want people to like you, ask them for advice instead of giving one.
Recently I was approached to give advice on learning and improving tech skills by someone not on my team. I agreed, though this was somewhat unexpected that someone would ask me this, like if I were any authority on the topic. “I know shit, why would you ask me anything?” where my initial thoughts. Whatever was the reason we spoke about different approaches to self-improving and especially techniques to deepen one’s technical knowledge.
The things that came from the top of my mind were these, and in this post I will give few thoughts on them:
- Learning Pyramid
- Deliberate practice
- Driving learning activities
- Dunning-Kruger effect
Learning Pyramid
Learning Pyramid is one one the learning models which stacks learning activities based on the retention rate of knowledge. Here is a table from wikipedia:
| Retention rate | Learning activity before test of knowledge |
|---|---|
| 90% | Teach someone else/use immediately. |
| 75% | Practice what one learned. |
| 50% | Engaged in a group discussion. |
| 30% | Watch a demonstration. |
| 20% | Watch audiovisual. |
| 10% | Reading. |
| 5% | Listening to a lecture. |
Source wiki: Learning pyramid
Effectively what it says is that using knowledge, practicing and teaching others is magnitude more effective than reading. When I think about this it seems somewhat paradoxical as often to teach someone or to practice you would actually need to read. The difference I could derive here is probably the timing of when the application of knowledge happens, i.e. if you read a short chapter on something and immediately try to use the knowledge vs. reading 20 chapters and then trying to do something about it.
The below is a technique of learning by Richard Feynman on the same lines. If you don’t know, Feynman was one of bright figures in science world. If you haven’t read “Surely You’re Joking, Mr. Feynman!” I would strongly recommend it.
The FEYNMAN technique of learning:
— Richard Feynman (@ProfFeynman) January 9, 2020
STEP 1 – Pick and study a topic
STEP 2 – Explain the topic to someone, like a child, who is unfamiliar with the topic
STEP 3 – Identify any gaps in your understanding
STEP 4 – Review and Simplify!
When I spoke with my colleague, I mentioned that brain processes of information retrieval are different from the processes of information storage. You make it one way road if you only read without practicing. This brings us to the next topic:
Deliberate practice
Not all practice is equal. After years in software I tend to do things the way I’m used to, despite knowing there might be better ways. This is not right as it is always a good idea to step back, see what you can do better, learn it, repeat few times to make it a habit and so on.
While regular practice might include mindless repetitions, deliberate practice requires focused attention and is conducted with the specific goal of improving performance.
by James Clear, from here: https://jamesclear.com/beginners-guide-deliberate-practice
I think looking at your own knowledge gaps, and spending time to explicitly work on those areas is probably the best you can do to improve. Sometimes you would need help to help you understand what the gaps are and what you can work on to improve. Unfortunately, just repeatedly doing what you already know might not help.
Driving learning activities
There are four different kinds of activities that I do at work to help others learn and to learn myself. Unfortunately I’m not sure if I can expand on what they are exactly, but in essence they are about sharing knowledge, encouraging others to share knowledge, discussions around concrete technical topics, and hypothetical problem solving. I encouraged the colleague of mine to do something similar in his team, starting with a small group of interested people and then extending if this goes well.
If you are reading this post and are interested in expanding your technical knowledge it might be a good advice for you – start some learning activity with the group of interested people (teammates, local nerds, etc). The activity could be anything that interests you in particular. This may sound selfish, but you will be the main beneficiary of such activity.
Dunning-Kruger effect
Let’s finish with the Dunning-Kruger effect – you know that plot of perceived knowledge versus actual knowledge over time. Here it is, in case you don’t remember:
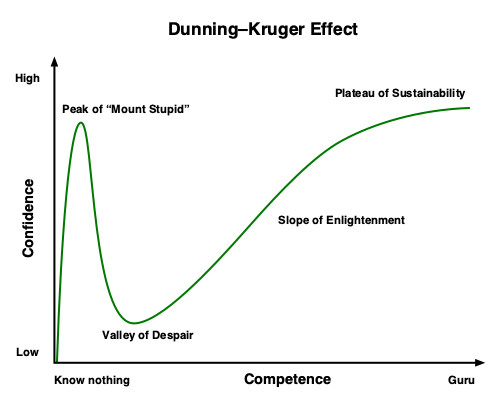
I’m definitely post “mount stupid” but I have no smallest idea where exactly – maybe still sliding down, who knows. There was time, maybe first 2-4 years into my career when I had enough confidence to give talks, write 100s of blog posts and write an e-book. Now I feel like I don’t know anything. Though, in retrospect, this should not be the reason not to do things. Doing is learning. This is also the reason I started writing more on the blog. So again, if you are still with me, doing things is always better than not doing them (kind of self-evident, I know). Reading is not enough (another sin of mine), applying knowledge is what makes you move forward!
Share in comments how you are working on your learning.
Technical Interview Cheatsheet
This blog post is a coding and system design interview cookbook/cheatsheet compiled by me with code pieces written by me as well. There is no particular structure nor do I pretend this to be a comprehensive guide. Also there are no explanations as the purpose is just to list important things. Moreover, this blog post is work-in-progress as I’m planning to add more things to it.
As always, opinions are mine.
Binary Search
Breadth First Search
Depth First Search
Just replace the queue in BFS with stack and you are done:
Backtracking
Generally a recursive algorithm attempting candidates and either accepting them or rejecting (“backtracking”) based on some condition. Below is an example of permutations generation using backtracking:
Dynamic Programming
Technique to determine result using previous results. You should be able to reason about your solution recursively and be able to deduce dp[i] using dp[i-1]. Generally you would have something like this:
Dynamic Programming: Knapsack
Union Find
When you need to figure out if something belongs to the same set you can use the following:
Binary Tree Traversals
- Inorder: left-root-right
- Postorder: left-rigth-root
- Preorder: root-left-right
- Plus each one of them could have reverse for right and left
Below are recursive and iterative versions of inorder traversal
Segment Tree
Djikstra
Simplest way to remember Djikstra is to imagine it as BFS over PriorityQueue instead of normal Queue, where values in queue are best distances to nodes pending processing.
Multi-threading: Semaphore
Multi-threading: Runnable & synchronized
Strings: KMP
Hopefully no one asks you this one. It would be too much code here, but the idea is not that difficult: build LPS (example “AAABAAA” -> [0,1,2,0,1,2,3]); use LPS to skip when comparing as if you were doing it in brute-force.
Strings: Rolling Hash (Rabin-Karp)
Let’s imagine we have window of length k and string s, then the hash for the first window will be:
H(k) = s[0]*P^(k-1) + s[1]*P^(k-2) + … + s[k]*P^0
Moving the window by one, would be O(1) operation:
H(k+1) = (H(k) – s[0]*P^(k-1)) * P + s[k+1]*P^0
Here is some sample code:
Unit Testing
JUnit User guide: https://junit.org/junit5/docs/current/user-guide/
Data Structures
Many interview problems can be solved by using right data structure.
- hashmap
- stack
- queue
- priority queue
- trees
- linked list
- …
- Actually, better to go here: https://www.geeksforgeeks.org/data-structures/
System Design Topics
- requirements gathering
- capacity planning
- high level design
- components design
- database design
- API design
- queue
- map reduce
- long poll and push models
- load balancing
- partitioning
- replication
- consistency
- caching
- distributed caching
- networking
System Design Interview Considerations
These are notes I took while reading “System Design Interview – An insider’s guide”:
- Chapter 1: Scale From Zero To Millions Of Users
- All of the most basic concepts introduced of a software design of a typical web application:
- Client/Server communication and DNS
- Load balancing and introduction of multiple servers
- Database replication with single master and multiple slaves and also later on database scaling
- Caching at the front of a database
- Content delivery Network (CDN) use for static content
- Stateless vs stateful server with clear preference for stateless
- Datacenters for more scale and for better reliability
- message queues for async operations and reducing spikes in load
- all of the auxiliary considerations for large system: logging, metrics, monitoring,
- Chapter 2: Back-of-the-envelope Estimation
- This is not something I have top of my mind when thinking about system design, but I guess it is important in the context of the interview to understand the scale of the system you are building.
- Some number:
- Transatlantic network roundtrip: Approximately 150ms
- Reading 1MB from memory: Around 250 microseconds
- Reading 1MB from network: Roughly 10ms
- Reading 1MB from disk: Typically 30ms
- Processor thread synchronization (mutex): As little as 100 nanoseconds
- Chapter 3: A Framework For System Design Interviews
- understand the problem and establish design scope
- propose high level design and get buy-in
- Design deep dive: work with interviewer to understand what they would like you to dive into, also don’t be shy to propose your own area for deep dive
- wrap up: you can reiterate over the design, mention other considerations you could have spoken about
- Chapter 4: Design A Rate Limiter
- using the framework from chapter 3 goes over designing rate limiter
- explains few different algorithms to rate limiter:
- token bucket – simple, used by Amazon, imagine a bucket, there is re-filler that just adds tokens periodically, if bucket is full tokens fall-out, every request takes out one token, if there are no tokens at given time request is rejected
- leaking bucket – FIFO
- fixed window counter
- sliding window log (expensive on memory as we need timestamps)
- sliding window counter
- Important to send back HTTP 429 with X-Ratelimit-Retry-After
- Talks about issues of using counters in distributed environment and how Redis distributed cache can be used as a solution
- More advanced rate limiting techniques are only mentioned, like limiting in network Layer 3 IPTables, not just layer7 HTTP
- Chapter 5: Design Consistent Hashing
- Explains hash space and hash ring – we place all n servers into a ring and then once we have hash key we find the server that has it on the ring by going clockwise
- Explains an issue with adding or removing servers (all data has to be copied over)
- Introduces concept of virtual nodes, this is same as used by Amazon Dynamo – one physical server owns multiple virtual nodes, this archives more balanced distribution of keys (we don’t end in situation when one servers owns majority of keys)
- Chapter 6: Design A Key-value Store
- This is basically copy-paste-simplify from Amazon Dynamo WP but explained in more accessible way
- Additionally starts with introducing the CAP Theorem
- Additionally mentions:
- gossip protocol – each server has heartbeat info about other servers and periodically “gossips” about it with other servers, once they see one of them is not really getting fresh heartbeats it is declared “dead”
- hinted handoff – process of communicating to the server that is known to be healthy and then once the server the data was intended for is back online the data is transferred to where it belongs
- Merkle tree is used to handle more permanent failures to reduce amount of data that has to be synchronized (we compare trees on two servers)
- Chapter 7: Design A Unique Id Generator In Distributed Systems
- Discusses how difficult it is to generate unique id in distributed environment if there are certain constrains, for instance we want ids to increment with time.
- Twitter snowflake is 64 bit id: 0 + 41bit timestamp + 5bit datacenter id + 5 bit machine id + 12 bits sequence number (restarted every ms)
- One core assumption of this is that we have distributed clock, which was outside of the scope of this chapter
- Chapter 8: Design A Url Shortener
- Well, we want a HashMap, but we want it distributed and persistent.
- Important to try to estimate. For instance we can calculate we need 36TB of space for 10 years with 100million URLs written per day. We can also estimate that we need Hash value length of 7 [0-9, a-z, A-Z] for storing those 365 billion records
- Discussed different hashing algorithms, CRC32, MD5, SHA-I and the issue that if we use them and then map into 7 value length we will run into collisions, thus we need to come up with technique where we first look into cache/db if the key is already present and if so, we need to re-hash
- Base62 conversion is another potential method to use. Basically we take sequential integer number (base 10, obviously) and convert to base 62, we end up with things like: 11157 => “2TX”
- URL redirect has to be 301 (permanent redirect) or 302 (temporary redirect). Temporary could be useful if we want analytics. Obviously for reducing load we might prefer to go with 301.
- Chapter 9: Design A Web Crawler
- Other than Google and other search engines crawling the internet there are numerous web archives that attempt to archive the internet. Web mining (news, knowledge) and web monitoring (copyrights, trademarks) are two other use-cases.
- Interesting and important considerations:
- content seen?
- Caching of DNS (yes ! Roundtripping to figure out IP could take time when we need to visit the same site 1000s of times, each DNS could be (10-200ms), so we store a map site->IP on our own.
- Blocklisting (sensitive content, etc)
- DFS isn’t the best choice as we will get stuck on the same website for too long
- BFS works for the most part but we still need to redistribute so that we don’t spend too much processing on a single site (like wikipedia)
- “Politeness” – yeah, we don’t want to aggressively bombarde the website. Funnily enough I have a personal story of a website of a metal band when they said they hid some nugget presents on their website, so I wrote a web crawler for their site and left it running all night. Next day the site was down. I probably wasn’t the only “smart” guy listening to them. LOL.
- Priority – we need to distinguish between important sites and not so important and also we need to think about frequency of updates of some sites (news)
- Robots.txt – Robots Exclusion Protocol is the way of websites to tell robots how they should behave 🙂
- Geography. Let crawlers located physically close to the website host crawl there.
- Spider traps – yeap. There are intentional and unintentional ones.
- Server side rendering. Since modern web often uses client side JS scripts to produce HTML we need to load the page and render before parsing.
- Chapter 10: Design A Notification System
- Notifications: SMS, email, push-notification. Is there more?
- For iOS we need to use Apple Push Notification Service. For Android Firebase Cloud Messageing is often used. For SMS Twilio, Nexmo are used. For email Sendgrid and Mailchimp.
- Normally a notification system is a component in a large system and services that perform some operations interact with it so that notifications are sent: [Services: 1-N]->[Notification System]->[ANPs, FMC, SMS, etc]->[User]
- We introduce queue per channel and workers consuming messages from the queue before they connect to 3rd party services.
- Message queues help with spike in volume of messages and also isolate different 3rd party dependencies (queue for SMS could be full but other queues get emptied)
- We need to add a notification log so we have record of what was sent to 3rd party.
- A key metric for monitoring is # of messages in the queue. Either capacity is not enough or 3rd parties aren’t keeping up/down.
- Analytics Service is another component to consider. Data can be sent to it from different points in the lifecycle of the notification (say, user clicked on a link in notification).
- Chapter 11: Design A News Feed System
- Key to this design is to take posted item (say Facebook post) and then place it into different processing systems, specifically:
- post service to properly store the post
- notification service to notify “friends” of the poster
- fanout service is to propagate the post to subscribers (“friends”)
- Fanout service that delivers the news can be implemented in two variations:
- on write (push model)
- precomputed, fast
- expensive if many friends or infrequent use of the app
- on read (pull model)
- A hybrid approach is usually best (think how Twitter does this for celebrities):
- push model for regular users so its fast
- pull model for subscribers of celebrities
- on write (push model)
- We use CDN for static content (images, videos)
- We use caching at multiple levels (news feed cache as people usually only interested in latest, user cache, post cache)
- Key to this design is to take posted item (say Facebook post) and then place it into different processing systems, specifically:
- Chapter 12: Design A Chat System
- One of the key concepts to know here is how clients connect:
- Polling – client periodically asks for data
- Long polling – client connects to data and server sends data back once it is available, connection maintained for longer period of time (30sec or something)
- WebSocket – bidirectional communication; client establishes the connection but server can then send data. Starts as a HTTP connection and then converts to WebSocket; works on same ports: 80 or 443 so should work everywhere.
- All of the authentication, metadata and other API work pretty much as in other systems.
- 1-1 chat works by two clients connecting to servers using WebSockets. Because one of the users might not be online we use message queue + keyvalue store to store messages and also a push notification is sent to another user about availability of new messages
- Facebook processes 60 Billion messages a day.
- Message synchronization is another important topic. Can be solved by client devices keeping max message id. Message ids should be sortable and represent a timeline.
- For a small group chat we can maintain “inbox” for each user and then we add messages to that inbox from other users
- Online presence is another interesting consideration. We shouldn’t be too eager to constantly know the status as network connection might not be stable.
- One of the key concepts to know here is how clients connect:
- Chapter 13: Design A Search Autocomplete System
- This is basically a huge Trie, that is built on periodic basis (say weekly) which is loaded into memory but also persisted to storage.
- Each node other than just having counter for occurrences also has cached list of top X results, in this way in order to provide autocomplete we just find the node and immediately have suggestions.
- Caching is important in multiple places
- clien browser. A header can be set “max-age=3600”. This is exactly what Google does.
- Updating TrieNodes on-the-fly is very expensive.
- A follow-up would be to support real-time search queries. An idea here could be to give more weight to more recent queries.
- Chapter 14: Design Youtube
- back of envelope for 5 million daily users
- 5 M * 10% (uploaders) * 300 MB (avg video) = 150TB
- CDN cost ~ $150K daily
- For video uploading
- we need transcoding servers, which could break video into smaller chunks and encode it to different sizes
- Storage for encoded videos
- CDN to have videos available for users
- completion handler to notify systems of completion of transcoding
- Streaming flow
- MPEG-DASH, Apple HLS, MS Smooth Streaming, Adobe HTTP Dynamic Streaming are different kinds of streaming protocols over HTTP
- Facebook is using directed acyclic graph (DAG) for processing videos. So, the root is the original video, children are: video, audio, metadata, Then children of “video” are: inspection, video transcoding, thumbnails, watermark, ect; Then child of video and audio is the re-assembled video
- Considerations:
- Cost of CDN (don’t keep long-tail videos in CDN as no-one is watching them)
- safety of videos (copyright, sensitive)
- back of envelope for 5 million daily users
- Chapter 15: Design Google Drive
- Consistency is extremely important here. We cannot lose data either.
- Two types of uploading files: resumable for small files and non-resumable for larger files.
- Files need to have revisions.
- Files need to be split into smaller chunks (Dropbox does 4MB).
- On upload we need to update only chunks that changed and can use checksums/hashes to verify what changed.
- Sync conflicts have to be handled by a client that was late to the party. This works similarly to have Amazon Dynamo handles this. Client gets two versions of a file and has to arrive at a merged version.
- Message database could be a proper relational SQL database. We will need to store users, files, file versions, chunks, devices.
- Chapter 16: The Learning Continues
- Reference material.
Resources
Well, internet is just full of all kinds of resources and blog posts on how to prepare for the technical interview plus there are numerous books and websites available. LeetCode is probably the most known of practicing websites. “Cracking The Coding Interview” is probably the most known book. I can also recommend “Guide to Competitive Programming”. As of system design, preparation resources are not so readily available. One good resource is “Grokking System Design Interview”, but it would be more valuable to practice designing large distributed systems. I also found the book “Designing Data-Intensive Applications” to be extremely helpful.
Asking for help
What are other “must know” algorithms and important system design topics to be listed in this post?
Book Review: “Why We Sleep”
February 2, 2020 Book Reviews No comments

I picked the book “Why We Sleep” for listening after seeing it recommended by Bill Gates and hearing endorsement from a coworker. If you are like most of hard working people, say a software development engineer, you might think adding few extra hours of work would help in your career – it might but NOT if you steal those hours away from night’s sleep as it is simply counterproductive and all the way detrimental to your health and creativity. Read or scroll through the post to understand why sleep is important.
Importance of Sleep
The book emphasizes importance of sleep by providing numerous studies and explanations into mechanics of sleep. The book explains the impact sleep has on the quality of health, both physical and mental, as well as it explains profound effects it has on memory. In addition to all of these, not too well understood and intriguing process of dreaming is covered in great detail. I totally loved it.
If you don’t have time to read the book or this post, read these two quotes and then make your own conclusion on whether you want to to have a second thought:
…our lack of sleep is a slow form of self-euthanasia…
– Matthew Walker, Why We Sleep: Unlocking the Power of Sleep and Dreams
the shorter your sleep, the shorter your life. The leading causes of disease and death in developed nations—diseases that are crippling health-care systems, such as heart disease, obesity, dementia, diabetes, and cancer—all have recognized causal links to a lack of sleep.
– Matthew Walker, Why We Sleep: Unlocking the Power of Sleep and Dreams
Let me take you through four parts of the book:
Part 1. This thing called sleep
This chapter introduces sleep and explains benefits of sleep for the brain and memory.
Basic concepts:
- Circadian rhythm – natural sleep-wake cycle which is roughly 24h15min.
- Melatonin – natural hormone signaling darkness. Something you might want to consider when battling effects of JetLag.
- REM – Rapid Eye Movements type of sleep. This is non deep sleep when your body is still switched off, but brain is relatively active. This is also the phase when you have your dreams.
- NREM – Non REM sleep type. This is sleep type with slow brain activity.
- Sleep stages – there are 3 stages of NREM sleep with different depth and 1 stage of REM sleep in a single sleep phase.
- Sleep phase – normally people get 4 or 5 sleep phases over night with REM sleep becoming longer towards morning.
Here is how it typically looks like:
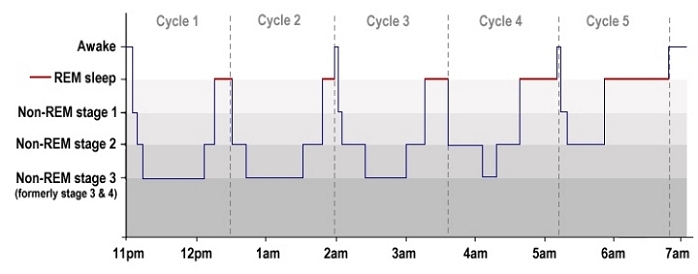
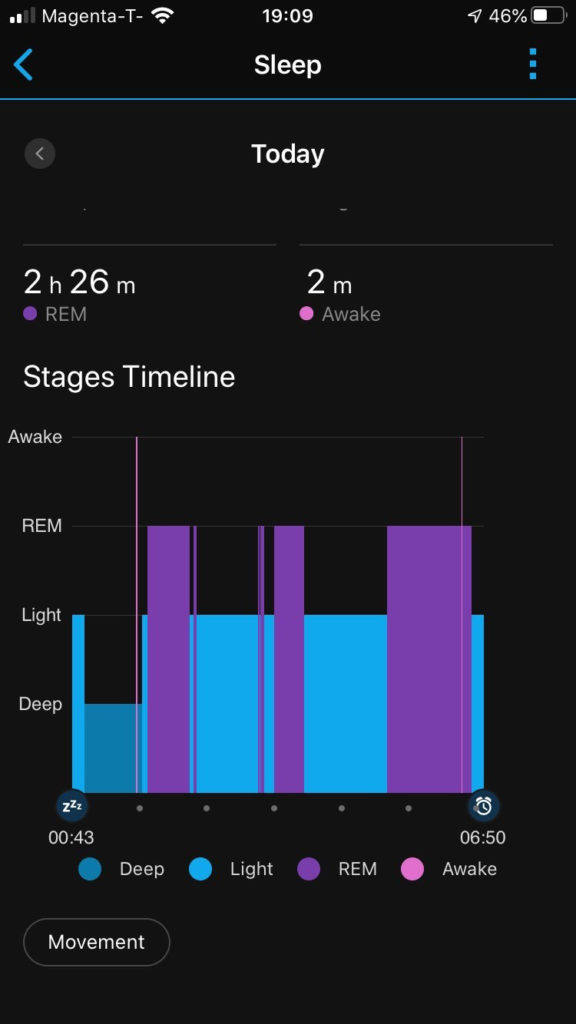
And this is how it might look for real (screenshot by a friend of mine):
When it comes to information processing, think of the wake state principally as reception (experiencing and constantly learning the world around you), NREM sleep as reflection (storing and strengthening those raw ingredients of new facts and skills), and REM sleep as integration (interconnecting these raw ingredients with each other, with all past experiences, and, in doing so, building an ever more accurate model of how the world works, including innovative insights and problem-solving abilities).
– Matthew Walker, Why We Sleep: Unlocking the Power of Sleep and Dreams
Other chapters of this part also cover how sleep is different in some animals (half-bran sleep, partial brain sleep); how sleeping patters change with our age (deep sleep in childhood, longer sleep for adolescent, fragmented sleep in midlife and old age); sleep differences in cultures (hunter-gatherer tribes, siestas in Greece).
Part 2. Why should you sleep?
Sleep is the aid for memory. It both helps you generate new memories and store new learnings. Moreover sleep helps with creativity.
Seven hours of sleep isn’t enough; concentration depends on sleep; you cannot catch up under-slept week days with even 3 long weekend recovery nights; no proof naps can replace sleep.
Another aspect is emotional stability. Just think how much agitated your kids are when they don’t get enough sleep. Adults are the same, though we are slightly better at suppressing our display of emotions.
The book then covers some areas of human health that are affected by sleep:
- length of your life and chances of diseases (obesity, dementia, cancer, etc);
- cardiovascular system (heart diseases);
- weight gain and obesity – simply put if you are trying to loose weight and don’t sleep enough you will have hard time;
- reproductive system – sleep loss reduces hormone levels, not even talking about looking unattractive;
- immune system – if you don’t sleep enough you have nigher chances to catch an infection.
Part 3. How and why we dream
Dreaming is a self therapy. What I remember from the book is that during REM sleep we cope with our emotional state, we heal ourselves.
REM sleep is the only time during the twenty-four-hour period when your brain is completely devoid of this anxiety-triggering molecule. Noradrenaline, also known as norepinephrine, is the brain equivalent to a body chemical you already know and have felt the effects of: adrenaline (epinephrine).
– Matthew Walker, Why We Sleep: Unlocking the Power of Sleep and Dreams
As I understand it – dreaming is a combination of past lived emotions and experiences from memories semi-randomly blended together sometimes generating patches of unusual display explaining creativity.
Lucid dreaming was another interesting topic covered in the book. 20% of people can control their dreams. My wife is good at this. I sometimes can make myself fly for longer, but that’s about it.
Part 4. From sleeping pills to society transformed
This part covers various sleep-related disorders and effects modern society has on quality of sleep (screen time, caffeine, alcohol, artificial light, room temperature) as well as sleeping pills (they are bad for your health and don’t really help too much).
Sleep therapy is one of the methods that really helps with sleep. One suggestion the book gives is to “reduce anxiety-provoking thoughts and worries”. If you know how the hell this can be done, let me know!
Twelve tips for healthy sleep
I just copy-pasted these 12 tips, but I do believe they are so important it does no harm to reiterate over them.
- Stick to a sleep schedule
- Don’t exercise too late in the day
- Avoid caffeine & nicotine
- Avoid alcoholic drinks before bed
- Avoid large meals and beverages late at night
- Avoid medicines that delay or disrupt your sleep (where possible)
- Don’t nap after 3pm
- Make sure to leave time to relax before bed
- Take a hot bath before bed
- Have a dark, cool (in temperature), gadget free bedroom
- Get the right sunlight exposure
- Don’t stay in bed if you (really) can’t sleep
Conclusion
I strongly recommend reading the book especially if you are not convinced that good night’s sleep is beneficial and are choosing to work long hours.
Have a good night’s sleep next night!
Thoughts on 5 more books
January 19, 2020 Book Reviews No comments
Not too long ago I wrote a post called “It’s all in your head: thoughts on 15 books“, since then I read few more non-technical books, which I will be covering here. Technical books are usually covered in via separate blog post, like this one on Designing Data-Intensive Applications. I don’t want to turn my blog into book reviewing site, but just listing book often helps me recall some of the interesting points, so please bear with me or just skip this post :)
Can’t Hurt Me

Out of the books in this list I liked this one the most for its story. The audiobook which I listened to on audible is compilation of narration with kind of podcast insertions and comments by the author and the narrator. This really makes the book alive, like if someone was telling you a story in person. And oh my goodness… the story is something – you get to understand that some people have nightmarish lives full of suffering and yet persevere.
The book is the inspirational autobiography of David Goggins who had horrible childhood, terrible start of his adulthood, and yet despite all the odds, he has found insane drive to accomplish unthinkable, almost inhuman things, like setting world record for pull-ups, running ultramarathons, and pushing the limits of what is though possible for human body.
Some quotes:
Everything in life is a mind game! Whenever we get swept under by life’s dramas, large and small, we are forgetting that no matter how bad the pain gets, no matter how harrowing the torture, all bad things end.
Be more than motivated, be more than driven, become literally obsessed to the point where people think you’re fucking nuts.
One of the other reasons I really liked the book is that is talks a lot about running and I like running. In fact, the book and a friend of mine motivated me to run until I exhausted myself (maybe state of mind as well), unfortunately that turned out in knee joint pain and only 33km run. Hoping to complete my loop some other time.
The Compound Effect

This book felt more like motivational rant by a training coach pushing you to build right habits and sticking to them. Not as foundational as “The Power of Habit” from the previous list I had, but way more inspiring. So if someone needs a little kick in the butt, this call for action book might work well. I don’t think it worked for me, though.
You will never change your life until you change something you do daily. The secret of your success is found in your daily routine.
Some of my thoughts on the compound effect
Some say, be 1% better than previous day, something like (1.01)^365 = ~37.78, which is ~3800% better, but I have a very serious reservation on this. Again on numbers: let’s say this is about workouts or running at which case gaining 1% actually hits the limits of human body. I took my best 10K number which is 54:59 (3299sec) – super slow when you compare to the world record of 26:17 (1577sec). Now let’s say I only do 1% improvement every day, or each other 3 day while training over 3 years, then I should be running 10K in 84 seconds with a speed 428km/h (900km/h for world record holder). Of course, this is ridiculous. My point here is that there are so many other things that do not fall under this rule. I bet that our mental capacities also have the limits as all of mental processing is built on top of physical brain. Again, each next 1% is exponentially harder to achieve.
David and Goliath

The other book I read earlier by Malcolm Gladwell was Outliers, which I remember as a really great eye-opener on explaining why some things stand out, therefore I was really happy to receive a recommendation to read another book by him.
The book wasn’t exactly what I expected, but I definitely found intriguing how we can look at well known historical stories from totally different perspective and how David’s approach has to be taken when you seem to be at complete disadvantage.
We all know the story of David and Goliath, but the truth is that there is nothing to be surprising about David winning the battle. Goliath is huge and cannot see, he cannot move quickly and range of his weapons are limited when David uses another approach, as put by the author:
[A] sling has a leather pouch with two long cords attached to it, and … a projectile, either a rock or a lead ball. … It’s not a child’s toy. It’s in fact an incredibly devastating weapon. … If you do the calculations on the ballistics, on the stopping power of the rock fired from David’s sling, it’s roughly equal to the stopping power of a [.45 caliber] handgun. This is an incredibly devastating weapon. … When David lines up … he has every intention and every expectation of being able to hit Goliath at his most vulnerable spot between his eyes.
So next time when you hear about the story don’t just think in terms of underdogs but also think in terms of underestimated but totally capable competitors.
Two more quotes:
You can’t concentrate on doing anything if you are thinking, “What’s gonna happen if it doesn’t go right?
The scholars who research happiness suggest that more money stops making people happier at a family income of around seventy-five thousand dollars a year. After that, what economists call “diminishing marginal returns” sets in. If your family makes seventy-five thousand and your neighbor makes a hundred thousand, that extra twenty-five thousand a year means that your neighbor can drive a nicer car and go out to eat slightly more often. But it doesn’t make your neighbor happier than you, or better equipped to do the thousands of small and large things.
Relentless

Found this one to be another motivational rant. Way-way too much about sports as for my taste. The quotes from the book, though, are quite motivational. But, again, as with any book like that – what matters is what you do afterwards. Not recommending this one.
How to Talk to Anyone

Not inspired to write a complete review here. The book, especially the first parts, is really helpful in understanding how some things could help you strike a good conversation with almost anyone, but it is too trickery for me. I anyway always spoil all of the good conversations at some point of time especially with people who are important to me. This post is a complete summary of the book (maybe 20 min read) and you are done: https://sivers.org/book/HowToTalkToAnyone Otherwise cannot recommend to read entire book.
Instead of conclusion
There is nothing to conclude here, I only ask you for recommendations of some good non-fictional books. Thank you so much for reading!
Gym, QuadTree, and k-d tree
January 12, 2020 Data Structures, Design, Fun 2 comments
Recently I went to a gym with a friend of mine and we had a chat about QuadTrees and k-d trees (yeah… don’t invite software engineers to your party – they will spoil everything). He asked me to explain what QuadTree is, and I said that it’s like binary tree just with four children instead of two. He then said it must be a variety of k-d tree. “Well…” – thought I – “probably, but I don’t know”. He explained that k-d trees as used to break k-dimensional space, which seemed reasonable as QuadTree is used to break two-dimensional space. Below are definitions of the two from wikipedia as well as some of context and my drawings.
QuadTree
A quadtree is a tree data structure in which each internal node has exactly four children. Quadtrees […] are most often used to partition a two-dimensional space by recursively subdividing it into four quadrants or regions.
https://en.wikipedia.org/wiki/Quadtree
Something like QuadTree could be used to compress images or to break a map of uneven density into regions where each node would have similar density.
For breaking a map, you can think of a designing a system that handles storage of information about restaurants and other points of interest. You would like to look up the information using your location on a map. Obviously downtown of a big city would have high density of these places and you might not want to show all of them to your user. So you would break you map into more quadrants few levels down, but on the outskirts you might have only few nodes that cover larger areas.
I just drew this process of compressing an image below. What you see on the bottom-left corner (SW) is an image, which was broken on bottom-right (SE) into 4 quadrants, each of which was broken into some more, but the moment either black or white occupied entire square the process stopped. Top-right (NE) is visualization of a compressed image (not too nice), and top-left (NW) is the QuadTree with some of the leafs pointing to their position on compressed image, which needed only 67 nodes and depending on how we store the data it could be insanely small amount of data required.

k-d tree
[…] k-d tree (short for k-dimensional tree) is a space-partitioning data structure for organizing points in a k-dimensional space. k-d trees are a useful data structure for several applications, such as searches involving a multidimensional search key (e.g. range searches and nearest neighbor searches).
https://en.wikipedia.org/wiki/K-d_tree
I didn’t draw anything for the k-d tree, but on very high level the idea is similar of breaking the space and going few levels down (there exists a generalization called binary space partitioning). With k-d tree the space is broken into TWO half-spaces by one of the dimensions instead of FOUR. Say, if it was “z”, then all children to the left will have “z” of smaller value than parent, and all to the right will have greater than parent. What I find interesting about k-d tree implementation is assigning axis to levels (root “x”, its children “y”, their children “z”, next level would be “x” again and so on for 3-dimensional space).
Conclusion
Don’t be like me, read a bit about these fascinating data structures and their application and who knows, you might be able to strike a great conversation in your local gym! :)
Approaching a software engineering problem
January 5, 2020 Career, Opinion, Success No comments
How we approach problems often defines whether we succeed or not or how hard success comes to us!

This blog post is my humble attempt to come up with some of problem solving advice for software engineers who are starting in their careers. Why would you listen to me? – You don’t have to. In fact, I would argue, that you shouldn’t take anyone’s advice at glance and at the same time be open to evaluate everyone’s advice and then make up your own mind. I do not have many credentials, other than 12 years of experience as a software engineer in various roles (SDE, Sr. SDE, Tech Lead) and various industries (outsourcing, online entertainment, nuclear energy, e-commerce). My experience is different and success is questionable. I am guilty of making career mistakes and solving problems the hard way. My hope here is that the below could save you from making same mistakes.
Worst mistake
The worst mistake of all is to die with regrets but, as not to get too philosophical, we are talking about software here. So…
It is totally normal to get stuck time to time on problems. If you never ever get stuck it might indicate that you are staying in your comfort zone impeding the speed of your progress. Therefore, imho, one of the worst things you could do to yourself at work is to let yourself stay stuck on a problem without any progress or learning and as a result with no advancement to your future career.
Understanding the problem
The first step to approaching a problem is understanding. You’ve got to identify the issues and envision how the success would look like. Sometimes this might be referred to as “working backwards”. More often than not, there will be preprocessing done by business analysts / project managers / senior engineers which results in some kind of requirements (stories, documents, tasks, etc). Your job as a software engineer is to first understand what is wanted from you. Simply state back to requirement givers in your own words what it would solved problem mean. Once you understand the problem completely proceed to the next step.
Strategizing
The second step is strategizing. You need to come up with a potential solution. You might want to brainstorm on options, evaluate them and try to come up with the best one. Decision matrixes and other techniques might help, but don’t bug yourself too much. At this step you might want to create a plan by breaking problem into smaller tasks. You might work on proof of concept or try one or few things out. I do not believe in plans themselves, but I do believe in planning as it makes you think hard about the approach. It is important not to get stuck in “analysis paralysis” mode, so once reasonable time is spent, move on to the next step even if somehow you don’t feel ready. You will never be fully ready. Take on the problem you’ve got. You might learn some new things when doing so which you didn’t anticipate.
Execution
The third step is approach execution. Doesn’t matter how great plan you had, if you fail to execute you fail. Say, you picked option x and it didn’t work out for you, do you continue to push for x or do you switch to option y, do you give up, do you seek help? What do you do? Do you feel how anxiety creeps in?
From my personal observations generally there are two types of execution: erratic and systematic.
Erratic
Basically you just start bashing the keyboard, throwing different copy-pasted blocks of code and praying it is going to work. This is that kind of approach when “<” didn’t work, so you replaced it with “<=” and it worked, but then you realized that your loop had to start with index 1 instead of 0, and so on. Eventually you arrive at the finish line. I bet that most of us, software engineers, have used this approach and it worked at times but then we felt uneasy about it.
Systematic
You think about each piece of code you write and consequences it is going to have, questioning each line of code and thoroughly testing the code. Why do I use “<” instead of “<=”? Why does the loop start at index 0? Should have I used thread-safe data structure here?How would this button look on small screen? Why does this API accept any number of items? I don’t know about framework ABC, so why not read a doc reference first? And so on – you question everything! This approach might seem like taking much more time and it does, but eventually written software has less bugs, is much more maintainable and truly solves the problem. Arguably, maturity of a software engineer can be recognized by observing them solving problems in this systematic way.
Some other bullet points
- Reiterating is fine. Although systematic approach wants you to think about each line of code, you might be overwhelmed to do so at once for larger project. In this case coming up with a “skeleton” solution that does something and then building on top of it (maybe changing few “bones” here and there) is totally fine. This goes along with agile methodology as well. Just don’t scarify quality with “oh, this will be one in the next iteration” and eventually never being done.
- Do not just copy-paste. As the joke goes: “Dev1: Damn, copied this from StackOverflow and it still doesn’t work. Dev2: Did you copy from the question or the answer?” Although copy-pasting from other parts of the project or SO, for that matter, is totally fine, what’s not fine is not understanding what you are coping or not questioning the quality of the piece of code you are copying. If the code was written by more senior developer or if most of the project is written “this was” this is not a valid justification to not try to see if anything about it could be improved. As a simple example, a developer before you might have took a shortcut by defining style right in html instead of moving it to a css class in separate file.
- “Don’t work hard – work smart” – although true, stinks. Most often I heard this from people who were lazier than others. There might be two types of laziness – a) the one that makes you procrastinate, and b) the one that makes you ingenious in problem solving. I’m fine with b) as long as it doesn’t come at cost of quality of your solution in terms of maintainability. Think of someone doing a+=b; b=a-b; a-=b; to swap two integers because they didn’t want an extra variable and now extrapolate this on on system design of your software where no-one could understand what the hell is going on. Long story short, you need to work hard and there is no way around it.
- Pause to learn and deliberately practice. At times you might come around something you haven’t worked with before. Stop! Take a moment to understand what it is. Reading one of two pages of documentation or going through “hello world” tutorial might save you a day or few. As an example, you might need to integrate a library into your project and it may look overwhelming as the project is huge. At this point it is best to implement simplest possible project with the library to understand how it works before spending days integrating it and then not understanding why it isn’t working.
- Seek help but do your due diligence. It is totally ok to ask others questions – this is the way to learn. At the same time it might not be appreciated to ask something that can be found online or in documentation with a simple query. Also learn to ask how to ask help http://xyproblem.info/
- Time bound. Never get stuck on something for too long. Put some boundaries for specific tasks. If x isn’t working, look at your strategy and unstuck yourself. You might need to escalate this with your manager.
- Clearly communicate. Very likely you are working in a team and have a manager. Work on improving your communication so that you can convey your status and whether you are blocked and need help. I would advice against obfuscating your status with needless information – just be honest if you are having difficulties.
- Retrospect and analyze if you can improve something for the future. Don’t just take everything at its “status quo”. Say, if environment setup for your project is difficult, and always takes time for engineers go ahead and improve it.
- Reasonably document your work. Chances are that someone will have to solve a similar problem or that you will need to explain your work at later stages. Documentation is just a tool to help you out in these situations.
- Add your bullet-points/thoughts/disagreements in comments!
Conclusion
It is in my personal view that approaching a software problem consists of 1) understanding the problem 2) strategizing about solutions and 3) execution of the strategy. Observation I have made over the years is that engineers tend to solve problems erratically or systematically. More systematic approach supplemented with the above bullet-pointed guidance might be helpful advice for starting software engineers, but be skeptical as this is purely an opinion. Enjoy and let me know if it helps.
2019 Recap / 2020 Plan
December 29, 2019 YearPlanReport 18 comments
My life is boring. Unlike many previous years, when I either moved a country, got a newborn, changed a job, or travelled tons of countries, 2019 turned out to be unremarkable in so many respects. I do not know if this could be because of not having a clear plan as I usually do (see my reports and resolutions for past years here) or if this is because of becoming older and less ambitious. Hoping my 2020 is going to be way more exciting and positive! Wishing you a very happy new year!

2019 Recap
Let me try to pull out at least something of notice for 2019:
- Technically travelled around the globe in 6 days (airports: YVR->HKG->SIN->BLR->HYD->STV->BOM->LHR->YVR). Not enjoyable at all
- Bungee jumped (pic above)
- Leaned to solve Rubik’s Cube (personal record 2m41s)
- Visited real home (Ukraine) and previous home (Austria)
- Drove from Vancouver all the way to Death Valley and back
- Ran 52 times with total distance 311 km
- Worked out 107 times
- Gained 7kg. Yes, on purpose and it wasn’t any easy as I’m super skinny guy with insanely high metabolism, yet after this my BMI is still < 20
- Set some personal records (half-marathon in 2h00m, 10km in 52:41, 1km in 3:50, longest run at 33km, pushups in a single set 101, pushups in single workout session 600, grouse grind of 2830 stairs in 46min)
- Listened to/read 24 books
- Managed to get at up around 5AM-6AM for couple of months and gave up
- Solved 282 leet code problems and haven’t given up yet
- Wrote 6 blog posts (shame!)
- I didn’t use Facebook, rarely used Twitter, watched only 2-3 TV series, went to cinema only once and this is all good (probably) except I cannot join all of the conversations
- “O, Canada!” is welcoming. I’m now a permanent resident and feel myself more like at home than I felt in Austria
Bad things:
- Created an instagram account and that thingy eats some of my time
- Cannot get up even within 1 hour after alarm going off
- Made very few friends (too few in fact)
- Visited 0 conferences
- Contributed to 0 open source projects
- Learned 0 new programming languages
- Learned 0 new frameworks
- Spoke at 0 events
- Got 0 promotions
- 0 interviews given [Edit 5Jan2020: from contact to offer or rejection]
- Can come up with N+1 things with number 0 and where I would want it to be > 0
- … you got the idea
Can have anything; cannot have everything
While some of those good things might seem interesting or even inspiring and some of bad things might not sound too horrible, I hate to celebrate. Problem is that I do not feel any progress in this year whatsoever. One intriguing thing that I came to realize is that I do have resources (relative youth, great health, some money) allowing me to do so many things, but sadly I cannot do everything I want and, maybe, I shouldn’t. Let me bring a quote from one of the books I read recently:
… you can have just about anything you want, but not everything you want. Maturity is the ability to reject good alternatives in order to pursue even better ones.
Ray Dalio, Principles: Life and Work
This is so sad! We don’t know what is right in this life and there is no “start over” button, at the same time “game over” is coming for everyone.
2020 Plan
So what’s up for the year 2020? A change! I don’t want any more children as two are already giving me hard time, but I don’t mind changing something about my work, learning something new and exciting, traveling somewhere exotic, or coming up with some fun that makes me and others happy.
Motto for the year 2020: “Break the records!“
Last updated 1 April 2020
- [Edit 29Jan2020] Spend more quality time with kids in 2020 than in 2019 as measured by wife’s opinion
- Travel
a distant country (candidate New Zealand, other places count)Changed thsi to be a long 2+ weeks roadtrip.- Write 24 blog posts, of which at least 12 are of a technical content
- Listen to/read 24 books
- Run 52 times
and take part in a race (candidate VanSunRun on 19April)- Ski 12 days (night skiing after work counts)
- Improve swimming by going 10 times to swimming pool (consider a course)
- Learn to walk on hands
- Work out 104 hours
- Gain another 7kg of pure muscles (70kg, BMI of 22, fat 11-15%)
- Drive a racing car
- Go indoor climbing 10+ times, learn to do 5.10+ YDS and V4+ Hueco (USA)
- Some adrenaline rush thingy (skydive, bungee, paraglide, etc)
- Learn a programming language (tiny project counts ~3 blog posts)
- (re)-introduce myself to Machine Learning (basics + TensorFlow)
- Sleep 8-9 hours, but learn to get up with damn alarm instantly (15 sec). This one might be the most challenging as this is a horrible habit of mine (hitting “snooze” for 2 hours)
- Limit read-only social media activities to 2 hours a week (scrolling Facebook/Twitter/Instagram/LinkedIn, excl. posting and messaging people) as to produce instead of consuming
- Meaningful work related change
- Solve 100 leet code problems
- Visit a tech conference and/or some tech meetup(s) (2+ counts)
- Quit regular money wasters (going out for lunch, 5$ coffee, etc, max 1 a week or 52 in a year)
- Reduce coffee (max 1 per day); best if I could go cold turkey
- Increase focus at work (track screen time and distractions)
- Invest 20% more money in 2020 than in 2019
Ok, these are 24 items. The goal is to complete at least 12 of them. Obviously some are more important and challenging like work related change and some are way less important and easy like learning to walk on hands, but, as a matter of fact, 92% of new year resolutions fail, so promising to do >=50% of the list might be a reasonable approach.
Happy New Year!
Dear reader, what’s your plan for the year 2020? Do you have one? Is it achievable and specific enough so you can keep yourself accountable?
- Travel
