January 12, 2020 Data Structures, Design, Fun 2 comments
Gym, QuadTree, and k-d tree
Recently I went to a gym with a friend of mine and we had a chat about QuadTrees and k-d trees (yeah… don’t invite software engineers to your party – they will spoil everything). He asked me to explain what QuadTree is, and I said that it’s like binary tree just with four children instead of two. He then said it must be a variety of k-d tree. “Well…” – thought I – “probably, but I don’t know”. He explained that k-d trees as used to break k-dimensional space, which seemed reasonable as QuadTree is used to break two-dimensional space. Below are definitions of the two from wikipedia as well as some of context and my drawings.
QuadTree
A quadtree is a tree data structure in which each internal node has exactly four children. Quadtrees […] are most often used to partition a two-dimensional space by recursively subdividing it into four quadrants or regions.
https://en.wikipedia.org/wiki/Quadtree
Something like QuadTree could be used to compress images or to break a map of uneven density into regions where each node would have similar density.
For breaking a map, you can think of a designing a system that handles storage of information about restaurants and other points of interest. You would like to look up the information using your location on a map. Obviously downtown of a big city would have high density of these places and you might not want to show all of them to your user. So you would break you map into more quadrants few levels down, but on the outskirts you might have only few nodes that cover larger areas.
I just drew this process of compressing an image below. What you see on the bottom-left corner (SW) is an image, which was broken on bottom-right (SE) into 4 quadrants, each of which was broken into some more, but the moment either black or white occupied entire square the process stopped. Top-right (NE) is visualization of a compressed image (not too nice), and top-left (NW) is the QuadTree with some of the leafs pointing to their position on compressed image, which needed only 67 nodes and depending on how we store the data it could be insanely small amount of data required.

k-d tree
[…] k-d tree (short for k-dimensional tree) is a space-partitioning data structure for organizing points in a k-dimensional space. k-d trees are a useful data structure for several applications, such as searches involving a multidimensional search key (e.g. range searches and nearest neighbor searches).
https://en.wikipedia.org/wiki/K-d_tree
I didn’t draw anything for the k-d tree, but on very high level the idea is similar of breaking the space and going few levels down (there exists a generalization called binary space partitioning). With k-d tree the space is broken into TWO half-spaces by one of the dimensions instead of FOUR. Say, if it was “z”, then all children to the left will have “z” of smaller value than parent, and all to the right will have greater than parent. What I find interesting about k-d tree implementation is assigning axis to levels (root “x”, its children “y”, their children “z”, next level would be “x” again and so on for 3-dimensional space).
Conclusion
Don’t be like me, read a bit about these fascinating data structures and their application and who knows, you might be able to strike a great conversation in your local gym! :)
Book Review: “Designing Data-Intensive Applications”
November 24, 2019 Book Reviews, Design No comments

The book “Designing Data-Intensive Applications” is definitely one of the best technical software engineering books I’ve ever read. Also it is probably the best one you can use to prepare for system design interviews in big tech companies, so take a note. I personally made three small tech talks within my tech team based on this book and plan to maybe do few more. Engineers love this stuff.
The book is very crisp and well structured dive into architecture of under-the-hood workings of distributed data systems, such as databases, caches, queues focusing on fundamentals rather than specific implementations. The book is also based on lots of scientific research which is properly referenced so you can always go deeper into any of given topics if you would like to.
Here is the list of all of the chapters, with some of the notes, and random comments from me (not well structured, but gives a good idea on what the book is about):
- Reliable, Scalable, and Maintainable Applications
- Martin Kleppmann brings in main terminology and fundamentals in this chapter:
- Reliable – system works correctly, even when faults happen.
- Scalable – strategies for keeping performance good under load.
- Maintainable – better life for engineering and operations.
- Martin Kleppmann brings in main terminology and fundamentals in this chapter:
- Data Models and Query Languages
- Data models as in three main types of databases: document, relational, and graph, and sometimes full-text search can be considered as another data model type.
- Storage and Retrieval
- Awesome chapter where the author builds database starting with simplest possible file commands like:
- And then expanding this to log-structured databases (Bitcask, SSTables, LSM-trees, Cassandra, Lucene, etc) and to update-in-place ones, with B-trees being the main example of these and core for effectively all relational databases.
- In this chapter the author also talks about two types of categories of databases – those optimized for transaction processing and those optimized for analysis.
- Encoding and Evolution
- This chapter is looking at different types of encoding, including popular JSON, XML but also those that are language specific or those that are used to write data to disk and also all kinds of problems that come with backwards compatibility and rolling upgrades.
- Replication
- The chapter on replication explains of single-, multi-, and no- leader replication, touching of potential problems you might face with them, such as “split brain“, “seeing into the future” because of the replication lag, etc, and solutions to those problems.
- Simple example of split brain is in single-leader replication when the leader node becomes temporary unavailable and one of the replicas is elected as leader, though when the old leader comes back online it still considers itself to be the leader. These inconsistencies and situations have to be be handled in properly designed distributed systems.
- Partitioning
- Key-range partitioning – partitions based on ranges of sorted keys.
- Hash partitioning – hash function applied to each key and partitions are based on ranges of hashes.
- Local document-partitioned indexes – secondary indexes stored in the same partition. Read requires scatter/gather across all partitions, write is to single partition.
- Global term-partitioned indexes – secondary indexes partitioned as well. Read from single partition, write to many.
- Transactions
- Race conditions:
- Dirty reads – read even before data committed.
- Dirty writes – another client overrides old uncommitted data.
- Read skew – client sees different parts of database at different times. Preventable by snapshot isolation.
- Lost updates – two clients in read-modify-write overriding each others data. Preventable by snapshot isolation or manual lock.
- Write skew – premise of the write decision changed since it was read by a transaction. Preventable by serializable isolation.
- Phantom reads – transaction reads data matching search conditions that are being changed by another client. Preventable by snapshot isolation.
- Serializable transaction types: executions in serial order, two-phase locking, serializable snapshot isolation.
- Race conditions:
- The Trouble with Distributed Systems
- All kinds of crazy things can go wrong when you are dealing with distributed systems are discussed in this chapter, including lost network packets, clocks going out of sync, temp failures of nodes, heck even sharks biting underwater network cables. Here is screenshot from youtube for fun:

- Consistency and Consensus
- Achieving consensus means making all of the nodes agree on irrevocable decision. One of the ways to achieve this without implementing own consensus algorithms is to “outsource” it to tools like ZooKeeper.
- Leaderless and multi-leader systems do not require consensus, but they need to cope with such problems as conflict resolution.
- Batch Processing
- Unix tools such as awk, grep, sort have the same processing principles as MapReduce. Same concepts extrapolate into dataflow engines as well. The author shows how two main problems of partitioning and fault tolerance are solved and then goes into join algorithms for MapReduce: sort-merge joins, broadcast hash joins, partitioned hash joins.
- Batch processing jobs read some input of data and produce some output, without modifying the bounded input.
- Stream Processing
- Stream processing is different to batch processing because the input is not bounded and is never-ending, therefore sorting does not make any sense and data is served by message brokers.
- Two types of message brokers are discussed: AMQP (order not preserved, messages assigned to consumers and deleted upon acknowledgment by consumer) and log-based (order preserved and same consumer receives all messages from same partition, messages retained and can be reread).
- The Future of Data Systems
- One of the interesting approaches to designing applications is to shift amount of work done from the read path to the write path. I.e. you would do more of preprocessing when writing via materialized views and caches so that when you need to read everything is prepared for you and query is super efficient. This technique is probably something that is used often when solving scaling and latency problems.
- I especially liked the last chapter on the Future of Data Systems and section “Doing the Right Thing” entertaining on implications of intensive data usage and trying to automate things based on data. One interesting thought experiment is to replace the word data with surveillance: “In our surveillance-driven organization we collect real-time surveillance streams and store them in our surveillance warehouse. Our surveillance scientists use advanced analytics and surveillance processing in order to derive new insights.” This becomes scary, especially when we try to justify automatically made decisions without looking at ethical implications. Another interesting quote brought in this sections is this “Machine Learning is like money laundering for bias“.
Conclusion
If you are software development engineer working on scalable distributed systems is book is simply must read. Totally and absolutely recommended. I will be going through some of the chapters once or twice again as one read is not enough. Let me end with this fancy quote brought up in the book:
“The major difference between a thing that might go wrong and a thing that cannot possibly go wrong is that when a thing that cannot possibly go wrong goes wrong it usually turns out to be impossible to get at or repair.” – Douglas Adams, Mostly Harmless (1992)
Approach to System Design Interview
October 7, 2019 Design, Interview, Opinion No comments
Designing something like Dropbox or other well known service is one of the standard System Design Interview (SDI) questions at FAANG companies. This post is for self-educational purposes focused on how to approach SDI question. Also this does not represent how any tech company is designing their software or is interviewing candidates. Though, feel free to use it as a guide for your SDI if you find it useful.
I like to break SDI into four phases. You want to get to the last phase when interviewer is making the problem harder by asking you follow up questions.
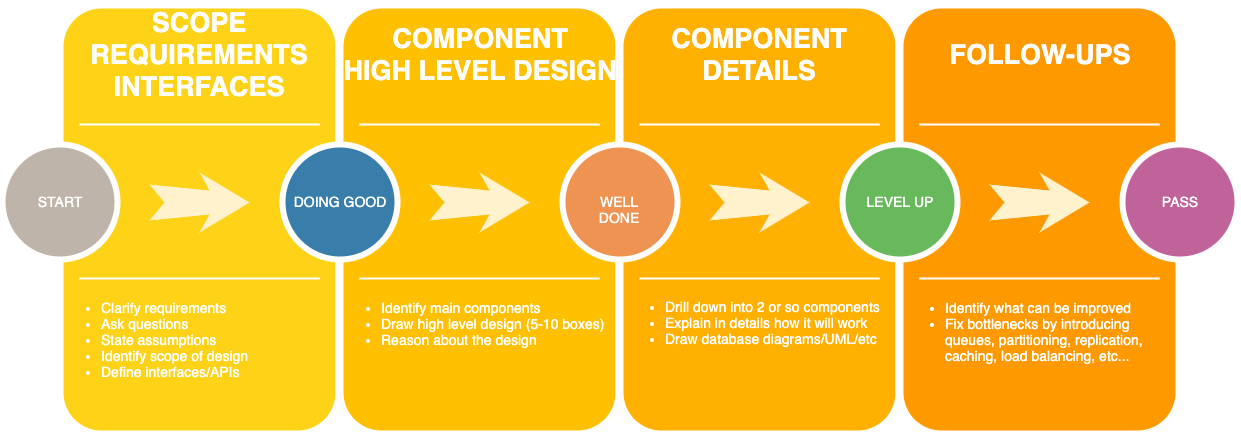
Scope, Requirements, Interfaces
The most important part that sets the tone for the entire interview is to clarify requirements with your interviewer. Try to understand what functional and non-functional scope of the problem they expect you to cover.
Functionally Dropbox “offers cloud storage, file synchronization, personal cloud, and client software”. You can list these as bullet points during the interview (any device accessibility, automatic file synchronization, file sharing, file storing, backups, team collaboration, security, etc).
Something like Dropbox will have to handle millions of users, have scalable, available, and performant backend. Ask for number of users, active users, devices, etc to be able to estimate required storage, network capacity and understand if partitioning and how much of replication of data is required. This can be used in calculations later on. Something like: 2K (avg. files) * 500Kb (avg. file size) * 1B (tot. users) ~= 1PB (file storage).
It is always a good idea to define interfaces of your system. APIs exposed by server are usually a great way to start. Define interfaces like list of REST calls or just names of APIs.
Component High Level Design
After gathering the requirements and documenting main interfaces proceed to listing major components of the system. You might not be able to list everything, so mentioning that there are other aspects that you not fully covering, but can get back to them when required (examples could be: authentication, payment system, integration with external systems, etc).
At this stage you should arrive at key ideas to solving the design. Key ideas for designing Dropbox could be: split large files into multiple chunks; keep chunk metadata in database locally and sync to server; receive and upload files via synchronization queues.
Once key solution ideas are clear, draw some boxes. It is best to start from top and proceed to details. In our Dropbox example it could be Backend and Frontend. Backend could consist of File Storage, Metadata Database, App Servers and Queues. Our Client could be split into logical parts. Many similar posts (not sure about origin) suggest to split client into Chunker (split files into multiple), Watcher (watches local folders and server for updates), Indexer (processes watcher events), InternalDb (stores metadata).
Component Details
Obviously, it is impossible to cover gigantic system, like Dropbox, in 45 minutes, so you have to focus on few aspects that are important. For instance, you can focus on database design for metadata by drawing tables and their relations, or instead you can focus on how updates will be sent to other devices by drawing sequence diagram, etc.
This could be the best stage to show your depth of the knowledge in one or the other area. More often then not interviewer would be happy to focus on area you are comfortable with and then would ask you follow-up questions to understand the depth of your knowledge and whether you really know what you are talking about or just making things up while throwing buzz-words. It should go without saying that you should not be doing this.
Follow-Ups
It is a very good sign when interviewer starts to make the problem harder as it means you are doing really good. At this stage the interview can go into any direction depending on the interviewer, but often you would need to solve scalability problems (queues, caches, load balancers), availability (replications), or you could be asked to increase the scope of functionality that would make you add new components, etc.
Conclusion
This is my concise view on the parts of SDI, though your experience could be totally different depending on the interviewer, company, level targeted and specifics of a question (like, say, designing fridge controller).
I recommend reading the book “Designing Data Intensive Applications” as it is absolutely great resource to train yourself whether you are preparing yourself for interview or just trying to solidify design skills. You can also try watching youtube videos and googling articles like this.
Why am I angry at developers? Is it factory? Is it testable?
October 17, 2011 Design 4 comments
Please take a look at this code snippet. What would you say about it?
public class TreatmentDataProviderFactory { private IDataAccess _dataAccess; private TreatmentDataProvider _treatmentDataProviderHost; private TreatmentDataProviderField _treatmentDataProviderField; public TreatmentDataProviderFactory(IDataAccess dataAccess) { _dataAccess = dataAccess; } public ITreatmentDataProvider Provider { get { if (SomeInteractionSingleton.PluginHost.GetWorkMode() == WorkMode.ConnectedMode) { if (_treatmentDataProviderHost == null) { _treatmentDataProviderHost = new TreatmentDataProvider(_dataAccess); } return _treatmentDataProviderHost; } else { if (_treatmentDataProviderField == null) { _treatmentDataProviderField = new TreatmentDataProviderField(_dataAccess); } return _treatmentDataProviderField; } } } }
Doesn’t it smell bad a lot?
1) Let’s start with obvious: properties in C# are not intended to be 10-20 lines long and having complex logic. Anyway I won’t wrote post if this was a problem.
2) Now the worst mistake here: how am I supposed to test this code if it uses SomeInteractionSingleton in the if condition. Why should this code be so coupled to SomeInteractionSingleton? I wrote this post because developer didn’t run tests. If he ran the tests, he would see they fail.
3) Now second bad mistake: this code keeps two instances of data providers. We can suppose that this is storage for two providers or something? :) I think GC is designed for something and lifecycle of objects shouldn’t be treated as this. I thought IoC is invented for something like this. At least developers should not keep code that much coupled and deliver creation logic.
4) Another mistake: Is this a Factory Method design pattern? – Almost. At least it has such name and looks like it (a bit). But it doesn’t meet either its original definition or either Parameterized Factory Method definition.
I redesigned this class. See:
public class TreatmentDataProvider { protected TreatmentDataProviderHost TreatmentDataProviderHost { get; private set; } protected TreatmentDataProviderField TreatmentDataProviderField { get; private set; } protected IPluginHost PluginHost { get; private set; } public TreatmentDataProvider(IPluginHost pluginHost, TreatmentDataProviderHost treatmentDataProviderHost, TreatmentDataProviderField treatmentDataProviderField) { PluginHost = pluginHost; TreatmentDataProviderHost = treatmentDataProviderHost; TreatmentDataProviderField = treatmentDataProviderField; } public ITreatmentDataProvider Provider { get { if (PluginHost.GetWorkMode() == WorkMode.ConnectedMode) { return TreatmentDataProviderHost; } else { return TreatmentDataProviderField; } } } }
Code above does the same logic, but it delivered control of creation of instances to other parties (IoC), also it now doesn’t have dependency on static methods, so code is less coupled. I didn’t remove this class as we have to keep verification for WorkMode at runtime. I know you might complain about these protected properties, but I like to have it that way for more flexibility when testing.
What are your thoughts? [Sentence removed 10/18/2011]
[Added 10/18/2011]
5) Yet another big mistake: Code reviewer. Guess who he was. When I’ve been reviewing this code by request of developer I just thought “it works, then it should be ok”. Why didn’t I ask about unit tests and why didn’t I took reviewing more scrupulously. I have to be more accurate when reviewing others code. Bad code reviewer.
6) Yet another mistake: writing this blog post. I understand that my criticism might be taken to close, especially if this was read. I also don’t like criticism. No one likes. Man, if you reading this you have to know I didn’t mean to abuse you or something, I just was upset at night about failing tests.
Few notes about Designing System
March 14, 2010 Book Reviews, Design No comments
Designing is “dry”, non-deterministic and heuristic process.
I just read one chapter from S. McConnell’s “Clean Code” book, and want make some review and summary without taking a look back into book. This should help me reinforce memories of what I’ve learnt.
When you are designing you always should keep in mind that you will not be able to make design good for all situations of life. Thus overthinking on problems could lead to overengineering, so you will get complex system with lot of unneeded tails. Future developers will not be able to work with your design. And project could even fail at some point of time.
To avoid this you should keep building system on easy to understand interfaces, that define how system behaves on different levels and that provide loose coupling.
Building your application like one solid system will lead to situation when you have everything coupled. I’m familiar with system, which is done like single exe file with more than 50 Mb size. You could not even imagine how everything there is coupled – you can get access to any part of the system from any other part. I understand that it is a legacy system and some things where done cause of ‘old school’ and so on and I understand that developers take this into account, but how on earth new guy will know how to work in that system? But how could it be sweet when you have system divided into subsystems, which of them has own responsibilities and depends only on one-two other subsystems, but at the same time provides functionality to good portion of other subsystems.
So, here we talk about low coupling, high cohesion and subsystems ordering. Here is how I do understand this terms:
Low coupling means that parts of the system should interact with each other by clearly defined interfaces, and you should work on decreasing number of interaction. Few characteristics that lead to low coupling are: Volume of connections should be low, Visibility of how two parts connects to each other should be high, Flexibility of changing connection should be also high.
High cohesion means that inside of one part of the system everything should be done compactly, part should have one responsibility well encapsulated inside.
Subsystems ordering means that once you have A and B, and B uses A, then A should not use B. If you need to grow your system you should decrease number of subsystems that you depend on and you should increase number of subsystems that depends on current subsystem. So you are getting tree.
When designing use Design Patterns. Why? Because they are found heuristically and if you think that you have a better decision to the same problem that known design pattern solves it is very possible that your solution will fail.
When designing ask Questions. Why? Designing is iterational process, you always can improve your solution. Just ask yourself if your current design is enough good and if so how could you prove that. Ask if there are other solutions to problem and why did you select your. Ask a lot. Invite a friend let he ask you.
You can design top-bottom and bottom-top ways. Use both. Why and how? Because they have advantages and disadvantages – you can get stuck with top-bottom if you will not have tech solution to some problem, that was defined at the top or solution is very cumbersome, also you can lost vision of what you do with bottom-top and will lost how to clue everything. We are all now far from waterfall so I think that nowadays it is possible to combine those two ways to design.
