May 16, 2010 .NET, Concurrency, MasterDiploma, Performance 4 comments
Few threading performance tips I’ve learnt in recent time
In recent time I was interacted with multithreading in .NET.
One of the intersting aspects of it is performance. Most of books says that we should not overplay with performance, because we could introduce ugly-super-not-catching bug. But since I’m using multithreading for my educational purposes I allow myself play with this.
Here is some list of performance tips that I’ve used:
1. UnsafeQueueUserWorkItem is faster than QueueUserWorkItem
Difference is in verification of Security Privileges. Unsafe version doesn’t care about privileges of calling code and runs everything in its own privileges scope.
2. Ensure that you don’t have redundant logic for scheduling your threads.
In my algorithm I have dozen of iterations on each of them I perform calculations on long list. So in order to make this paralleled I was dividing this list like [a|b|c|…]. My problem was in recalculating bounds on each iteration, but since list is always of the same size I could have calculating bounds once. So just ensure that don’t have such crap in your code.
3. Do not pass huge objects into your workers.
If you are using delegate ParameterizedThreadStart and pass lot of information with your param object it could decrease your performance. Slightly, but could. To avoid this you could put such information into some fields of the object that contains method for threading.
4. Ensure that you main thread is also busy guy!
I had this piece of code:
for
(int i = 0; i < GridGroups;
i++)
{
ThreadPool.UnsafeQueueUserWorkItem(AsynchronousFindBestMatchingNeuron,
i);
}
for (int i = 0; i < GridGroups;
i++) DoneEvents[i].WaitOne();
(int i = 0; i < GridGroups;
i++)
{
ThreadPool.UnsafeQueueUserWorkItem(AsynchronousFindBestMatchingNeuron,
i);
}
for (int i = 0; i < GridGroups;
i++) DoneEvents[i].WaitOne();
Do you see where I have performance gap? Answer is in utilizing my main thread. Currently it is only scheduling some number of threads (GridGroups) to do some work and than it waits for them to accomplish. If we divide work to approximately equivalent partitions, we could gave some work to our main thread, and in this way waiting time will be eliminated.
Following code gives us persormance increase:
for
(int i = 1; i < GridGroups;
i++)
{
ThreadPool.UnsafeQueueUserWorkItem(AsynchronousFindBestMatchingNeuron,
i);
}
AsynchronousFindBestMatchingNeuron(0);
for (int i = 1; i < GridGroups;
i++) DoneEvents[i].WaitOne();
(int i = 1; i < GridGroups;
i++)
{
ThreadPool.UnsafeQueueUserWorkItem(AsynchronousFindBestMatchingNeuron,
i);
}
AsynchronousFindBestMatchingNeuron(0);
for (int i = 1; i < GridGroups;
i++) DoneEvents[i].WaitOne();
5. ThreadPool and .NET Framework 4.0
Guys, from Microsoft improved performance of the ThreadPool significantly! I just changed target framework of my project to the .Net 4.0 and for worst cases in my app got 1.5x time improvement.
What’s next?
Looking forward that I also could create more sophisticated synchronization with Monitor.Pulse() and Monitor.WaitOne().
Good Threading Reference
Btw: I read this quick book Threading in C#. It is very good reference if you would like to remind threading in C# and to find some good tips on sync approaches.
P.S. If someone is interested if I woke up at 8am. (See my previous post). I need to say that I failed that attempt. I woke at 12pm.
Moving C# code to Java
May 9, 2010 C#, Java, MasterDiploma, Opinion 4 comments
Is CLR worse than JVM or it is just because my code is bad?
Today I had conversation with one man, who is great defender and evangelist of Java related technologies.
We talked about some algorithm implemented by me with C#. That is implementation of SOM algorithm and Concurrency stuff for it. My concurrency implementation doesn’t show time improvements unless grid size is big. He was able to achive better result with small grid sizes.
There could mean two reasons:
- CLR concurrency model gives up in front of JVM concurrency
- My implementation has gaps… which is more likely :)
Taking into consideration that I’m getting better results when grid is of bigger sizes I could suppose that in my algorithm there is code which takes constant (or near that) time and is not paralleled.
When I look at picture of Task Manager when my programm is executing I see that second processor has gaps when it does nothing:

This could mean only one: I need to take better look what else is executed in one thread in my application and could be paralleled.
Converting C# code to Java
But back to that man and Java. I said to myself that it is possible to move my code to Java if something.
C# to Java Converter
Download C# to Java Converter demo version from here. Since it is demo you could not convert more than 1000 lines of your code. Order costs 119$.
Because of that I was forced to remove all not necessary code. I removed all concrete classes that I’m not using and GUI, but that did not help. I did not know how much should I delete more.
Number of lines in my project/solution
I googled for line numbers in C# and found this nice tool:
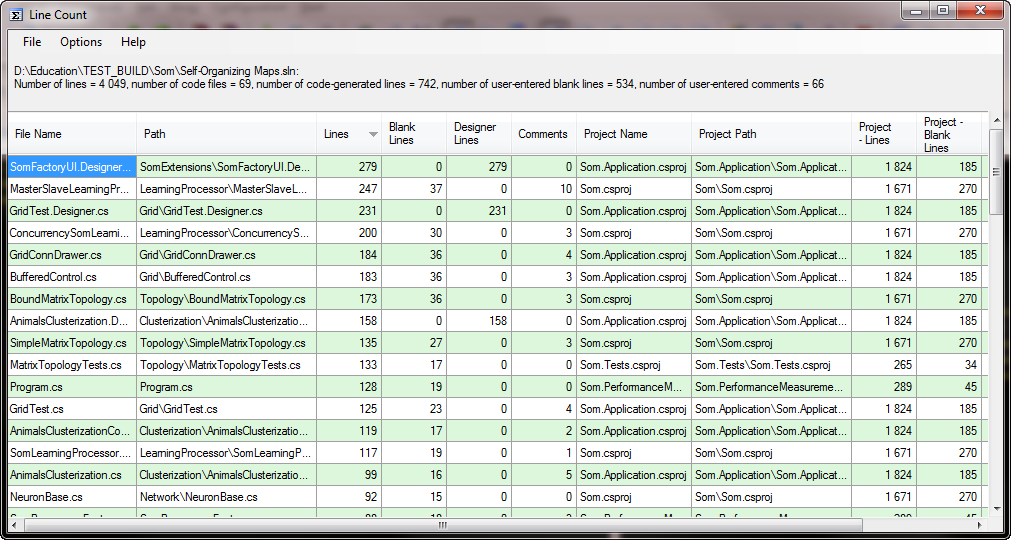
Now I know that my program has about 4000 lines of code. I left about 980 lines of code in two projects that I needed and was porting them to Java separately.
Converter GUI
And converted them to Java:
Is conversion an easy task?
Conversion could be painful if you have a lot of code that interacts with system, like threads, reading and writing to files, reading configuration file, etc.
Also it was not able to recognize ‘var’ keyword. It shows me this:
//C#
TO JAVA CONVERTER TODO TASK: There is no equivalent to implicit typing
in Java:
var neuronsCount =
getNetwork().getNeurons().size();
TO JAVA CONVERTER TODO TASK: There is no equivalent to implicit typing
in Java:
var neuronsCount =
getNetwork().getNeurons().size();
I moved back to my C# code and changed all var to the explicit types. And regenerated Java code.
There were some troubles when I’m delivering from List<T> and doing some stuff around that.
This code:
int a =
this[next];
this[next] = this[i];
this[i] = a;
this[next];
this[next] = this[i];
this[i] = a;
I rewrote manually to:
int a =
super.get(next);
super.set(next, super.get(i));
super.set(i, a);
super.get(next);
super.set(next, super.get(i));
super.set(i, a);
Also Converter was not able to convert this:
Console.ReadKey();
The biggest challenge is ThreadPool and synchronizing threads tech-nicks. This requires lot of google search that shows me that instead of ManualResetEvent I could use CyclicBarrier and how to utilize thread queuing in Java.
P/S I need to find gaps in my code to show that at least CLR and myself are not so much bad things in this world :)
Масштабування обчислень в SOM
May 7, 2010 MasterDiploma, Ukrainian No comments
Одним із найважливіших завдань для реалізації масштабування обчислень є знаходження частин алгоритму, які можна та які є оптимально розбити на деякий набір незалежних обчислень.
Велика кількість роботи по розробці масштабування обчислинь алгоритму SOM була зроблена за останні роки. Взагалі кажучи існує два основних підходи, якими є розбиття гратки (map-partitioning, MP) та розбиття даних (data-partitioning, DP).
В MP, SOM є розподілена поміж декількох потоків, таким чином, що кожен потік обробляє кожен вхідний вектор і модифікує свою частину гратки. Такий підхід зберігає порядок оновлень записаних у формулі [осн. формула оновлення]. Найбільшим недоліком цього методу є велика ціна синхронізації потоків, потоки повинні бути синхронізовані опісля кожного разу, коли був знайдений нейрон-переможець, а також кожного разу, коли пройшло оновлення. Таким чином MP є ефективним для хардверної реалізації або ж для систем із спеціальною архітектурою для паралелізації.
В DP, вхідні дані розподілені поміж потоками, так, що кожен потік містить частину вхідних даних та проганяє її на своїй копії гратки. Як бачимо цей підхід не вимагає частої синхронізації, таким чином це є перевагою над MP. Проте такий підхід не відповідає формулі оновлення, що змушує використовувати його із варіаціями SOM, зоокрема batch SOM. Та навіть попри це batch SOM не є популярним методом, із-за двох основних причин:
1. Він вимагає щоб усі вхідні вектори були наперед відомими, що не є завжди можливо.
2. Насправді дуже важко отримати добре структуровану карту на відміну від класичного алгоритму.
Існує також багато інших розробок. Для прикладу в одній із таких автори пропонують підхід схеми Master-Slave, яка базується на тому факті, що із часом радіус, у якому ми модифікуємо нейрони зменшується, а тому два послідовні нейрони-переможці можуть не мати спільних областей. Таким чином можна обробляти ці нейрони разом із частиною матриці в паралельних потоках. Master потік слідує за основними кроками класичного алгоритму, а Slave пробує здійснити обчислення в паралельному потоці для наступного нейрона переможця якщо області не перетинаються.
Мною була здійснена реалізація MP підходу до розпаралелення алгоритму із невеликими відмінностями.
Основною відмінністю є те, що в стандартній реалізації MP гратка розбивається на декілька підграток, скажімо на n частин. Опісля для заданого вхідного вектора ми шукаємо нейрон переможець у кожній із підграток в паралельних потоках. Як тільки він був знайдений, ми запускаємо модифікацію на тих самих частинах гратки. Якщо глянути на рисунку нижче, то можна побачити, що в такій ситуації для модифікації ефективно використовується лишень четвертий потік, перший та третій швидко впорюються із роботою, а другий потік взагалі простоює.

Я пропоную знайдену множину сусідів знову поділити на рівні частини, як це зображено на наступному рисунку, проте із певною відмінністю. Якщо множина нейронів для модифікації є більшою за число M, то я розбиваю цю множину на ту ж саму кількість що й розбивав гратку, і запускаю оновлення в різних потоках (перевикористовуються вже існуючі). Якщо число нейронів для модифікаціх менше за M, то модифікація проганяється в одному потоці. Число М має залежати від ціни синхронізації і ще потребує додатковго дослідження.

Такий підхід дає помітні покращення коли гратка є дуже виликих розмірів.
My implementation of Self-Organizing Map
March 24, 2010 KohonenAlgorithm, MasterDiploma No comments
Lets quickly remind how does Self-Organizing Map works and which are building blocks of it.
In my implementation I have processor named SomLearningProcessor which does all main algorithm steps. After you created instance of that class you are able to call void Learn() method, which goes through all iterations finds best matching neuron with method int FindBestMatchingNeuron(double[] dataVector) and then it accommodates network with using dataVector and found BMN – this is done with method void AccommodateNetworkWeights(int bestNeuronNum, double[] dataVector, int
iteration). I will return back to this processor with more details, I just wanted to give quick vision what is it.
So lets move to building blocks of our learning algorithm:
Network
First of all it has Network, which I inject into our SomLearningProcessor through the INetwork interface:
public interface INetwork
{
IList<INeuron> Neurons { get; set; }
ITopology Topology { get; set; }
}
As you see it has list of Neurons which should fill the leaning grid, which is provided through the Topology interface. The default implementation of the network interface supplies possibility to randomize neurons with specifying minWeights and maxWeights boundaries for randomizing.
public class NetworkBase : INetwork
{
public NetworkBase(bool randomize, IList<double> maxWeights, IActivationFunction activationFunction, ITopology topology)
{…
Also we are injecting IActivationFunction for our neurons, so they will calculate reaction basing on this interface. Interface provides method double GetResult(double inputValue);
There are following concrete implementations of the interface IActivationFunction:
- HardLimitActivationFunction
- LinearActivationFunction
- SymmetricHardLimitActivationFunction
- TransparentActivationFunction
For Self-Organizing Maps I’m using TransparentActivationFunction, which just returns summarized value.
Topology
Another interesting thing that we are using during learning process is Topology. Interface looks like this:
public interface ITopology
{
int
NeuronsCount { get; }
NeuronsCount { get; }
int RowCount { get;
}
}
int ColCount { get;
}
}
double WholeTopologyRadius { get; }
int
GetNeuronNumber(Location
location);
GetNeuronNumber(Location
location);
Location
GetNeuronLocation(int neuronNumber);
IList<int> GetDirectlyConnectedNeurons(int neuronNumber);
Dictionary<int, double>
GetNeuronsInRadius(int neuronNumber, double radius);
GetNeuronsInRadius(int neuronNumber, double radius);
}
As you see Topology consists with Rows and Columns as usual matrix, but the main point of interest is the method: Dictionary<int, double>
GetNeuronsInRadius(int neuronNumber, double radius); What does it do?
For the found best matching neuron neuronNumber – it should find all neurons which are located in boundaries of provided radius. Please also note that I’m returning pairs <NeuronNumber, DistanceFromItToBMN> in result dictionary. This allow increase performance a bit, because no need to double calculate distances.
Currently I have two finished implementations of ITopology they are SimpleMatrixTopology and BoundMatrixTopology.
Difference between them is that BoundMatrixTopology is closed cover like on the picture below, for matrix 6×5 and winning neuron number 22 with radius 2.1 it returns following neighbor neurons.

As you see it also returned 4 as connected neuron.
Same situation for SimpleMatrixToplogy returns next:

So far we have visual explanation how it searches for the neighbor neurons. On the picture below we could see which distances are returned by the
GetNeuronsInRadius method.

For my research I’m using SimpleMatrixTopology because it is much faster than BoundMatrixTopology.
A bit about Learning Process
Learning process is build upon changing weights of the neurons in order to be more close to input data vector. But also with increasing iteration number we should shrink the radius where we search for neighbor neurons and we should decrease learning rate. Also those neurons which are close to winner should be modified more than those which are far from it. This purposes are supplied by three interfaces. They are IRadiusProvider, INeighbourhoodFunction and ILearningFactorFunction.
RadiusProvider
Answers for the question which radius we should take on the n-th iteration. Currently I have one implementation of the interface, which looks like below:
public class DefaultRadiusProvider : IRadiusProvider
{
public int MaxIterations { get; private set; }
public double
TopologyRadius { get; private set;
}
TopologyRadius { get; private set;
}
public
double TimeConstant { get; private
set; }
double TimeConstant { get; private
set; }
public
DefaultRadiusProvider(int
maxIterations, double startRadius)
DefaultRadiusProvider(int
maxIterations, double startRadius)
{
MaxIterations = maxIterations;
TopologyRadius = startRadius;
TimeConstant = maxIterations / Math.Log(startRadius);
}
public double GetRadius(int
iteration)
iteration)
{
return
TopologyRadius*Math.Exp(-iteration/TimeConstant);
TopologyRadius*Math.Exp(-iteration/TimeConstant);
}
}
As you see when we create instance of it we define TimeConstant and that stands for:

when we calculate radius we are using next formula:

In those two formulas δ0 is half of the initial Grid radius and I setup it in constructor of Topology like: Math.Max(ColCount, RowCount) / 2.0, but of course we could choose wider initial value.
NeighbourhoodFunction
The most commonly used is Gauss Neighbourhood function, because it is quite smooth.
public class GaussNeighbourhoodFunction : INeighbourhoodFunction
{
public
double GetDistanceFalloff(double distance, double
radius)
double GetDistanceFalloff(double distance, double
radius)
{
double denominator = 2 *
radius * radius;
return Math.Exp(- distance / denominator);
}
}
We provide two parameters one of them is distance between neuron i and neuron j, another parameter is current radius, calculated by RadiusProvider. So the formula of it is:

LearningFactorFunction
And as we said before, learning rate should decrease with time. For this purpose I have few implementations of the interface ILearningFactorFunction. I’m using ExponentionalFactorFunction
which has method:
public
override double
GetLearningRate(double iteration)
override double
GetLearningRate(double iteration)
{
return StartLearningRate * Math.Exp(- iteration /
MaxIterationsCount);
MaxIterationsCount);
}
The formula looks like:

where τ2 is equal to maximum iterations count and η0 is starting learning rate. I set it to the 0.07.
Other Interfaces
During learning process I’m using few other interfaces. They are:
ShuffleProvider – provides method using which I shuffle input space vectors on each epoch.
LearningDataProvider – gives us possibility to get i-th input vector and answers for questions how many there are vectors and what is the dimension of input space. Using this interface I can mask providing of completely random input vectors as I did in this application. Or I can provide DataPersister into it, so it will be able read data from file or whatever.
MetricFunction – is just distance measurement for our grid. I have CityBlocks and Euclidean implementations.
SomLearningProcessor
With mix of all described above we can build our Learning Processor. Below is full code snippet of SomLearningProcessor:
public class SomLearningProcessor
{
public INetwork Network { get; private
set; }
set; }
public ITopology Topology { get; private set; }
protected
IShuffleProvider
ShuffleProvider { get; set; }
IShuffleProvider
ShuffleProvider { get; set; }
protected ILearningDataProvider LearningDataProvider { get; set; }
protected
IRadiusProvider
RadiusProvider { get; private set;
}
IRadiusProvider
RadiusProvider { get; private set;
}
protected
INeighbourhoodFunction
NeighbourhoodFunction { get; set; }
INeighbourhoodFunction
NeighbourhoodFunction { get; set; }
protected IMetricFunction MetricFunction { get; set; }
protected
ILearningFactorFunction
LearningFactorFunction { get; set; }
ILearningFactorFunction
LearningFactorFunction { get; set; }
protected
int MaxIterationsCount { get; set; }
int MaxIterationsCount { get; set; }
public SomLearningProcessor(
ILearningDataProvider
learningDataProvider,
learningDataProvider,
INetwork network,
IMetricFunction
metricFunction,
metricFunction,
ILearningFactorFunction
learningFactorFunction,
learningFactorFunction,
INeighbourhoodFunction
neighbourhoodFunction,
neighbourhoodFunction,
int maxIterationsCount,
IShuffleProvider
shuffleProvider)
shuffleProvider)
{
LearningDataProvider =
learningDataProvider;
learningDataProvider;
Network =
network;
network;
Topology =
network.Topology;
network.Topology;
MetricFunction =
metricFunction;
metricFunction;
LearningFactorFunction = learningFactorFunction;
NeighbourhoodFunction = neighbourhoodFunction;
MaxIterationsCount =
maxIterationsCount;
maxIterationsCount;
ShuffleProvider = shuffleProvider;
RadiusProvider = new DefaultRadiusProvider(maxIterationsCount,
Topology.WholeTopologyRadius);
Topology.WholeTopologyRadius);
}
public virtual
void Learn()
void Learn()
{
int vectorsCount =
LearningDataProvider.LearningVectorsCount;
LearningDataProvider.LearningVectorsCount;
IList<int> suffleList = new ShuffleList(vectorsCount);
for (int
iteration = 0; iteration < MaxIterationsCount; iteration++)
iteration = 0; iteration < MaxIterationsCount; iteration++)
{
suffleList = ShuffleProvider.Suffle(suffleList);
for (int
dataInd = 0; dataInd < vectorsCount; dataInd++)
dataInd = 0; dataInd < vectorsCount; dataInd++)
{
double[] dataVector =
LearningDataProvider.GetLearingDataVector(suffleList[dataInd]);
LearningDataProvider.GetLearingDataVector(suffleList[dataInd]);
int bestNeuronNum =
FindBestMatchingNeuron(dataVector);
FindBestMatchingNeuron(dataVector);
AccommodateNetworkWeights(bestNeuronNum, dataVector, iteration);
}
}
}
protected
virtual int
FindBestMatchingNeuron(double[]
dataVector)
virtual int
FindBestMatchingNeuron(double[]
dataVector)
{
int result = -1;
Double minDistance = Double.MaxValue;
for (int i
= 0; i < Network.Neurons.Count; i++)
= 0; i < Network.Neurons.Count; i++)
{
double distance =
MetricFunction.GetDistance(Network.Neurons[i].Weights, dataVector);
MetricFunction.GetDistance(Network.Neurons[i].Weights, dataVector);
if
(distance < minDistance)
(distance < minDistance)
{
minDistance = distance;
result = i;
}
}
return
result;
result;
}
protected
virtual void
AccommodateNetworkWeights(int
bestNeuronNum, double[] dataVector, int iteration)
virtual void
AccommodateNetworkWeights(int
bestNeuronNum, double[] dataVector, int iteration)
{
var radius = RadiusProvider.GetRadius(iteration);
var
effectedNeurons = Topology.GetNeuronsInRadius(bestNeuronNum, radius);
effectedNeurons = Topology.GetNeuronsInRadius(bestNeuronNum, radius);
foreach (var
effectedNeuron in
effectedNeurons.Keys)
effectedNeuron in
effectedNeurons.Keys)
{
var
distance = effectedNeurons[effectedNeuron];
distance = effectedNeurons[effectedNeuron];
AccommodateNeuronWeights(effectedNeuron, dataVector, iteration,
distance, radius);
}
}
protected
virtual void
AccommodateNeuronWeights(int
neuronNumber, double[] dataVector, int iteration, double
distance, double radius)
virtual void
AccommodateNeuronWeights(int
neuronNumber, double[] dataVector, int iteration, double
distance, double radius)
{
var neuronWghts =
Network.Neurons[neuronNumber].Weights;
Network.Neurons[neuronNumber].Weights;
var
learningRate = LearningFactorFunction.GetLearningRate(iteration);
learningRate = LearningFactorFunction.GetLearningRate(iteration);
var
falloffRate = NeighbourhoodFunction.GetDistanceFalloff(distance,
radius);
falloffRate = NeighbourhoodFunction.GetDistanceFalloff(distance,
radius);
for (int
i = 0; i < neuronWghts.Length; i++)
{
double weight = neuronWghts[i];
neuronWghts[i] += learningRate * falloffRate *
(dataVector[i] – weight);
}
}
}
Lets talk a bit about each of the methods.
public virtual
void Learn()
It is the main public method which could be used in outside world, so ti will learn Network using all stuff that we injected in constructor. After Lean has executed usage code could use learned Network through the public property. What this method does is: it goes through all iterations up to MaxIterationsCount, then shuffles input space (or not shuffles, it depends on shuffling provider), finds Best Matching Neuron and Accommodates Network weights.
protected
virtual int
FindBestMatchingNeuron(double[]
dataVector)
Is the most expensive operation. As you see it goes through all the neurons in Network and calculated distance from current neuron to dataVector. Then it returns neuron with minimal distance.
protected
virtual void
AccommodateNetworkWeights(int
bestNeuronNum, double[] dataVector, int iteration)
Takes BMN number, asks RadiusProvider for the radius on current iteration and then asks Topology to find all neurons connected to BMN in current radius. For each found neuron it accommodates weights in next method.
protected
virtual void
AccommodateNeuronWeights(int
neuronNumber, double[] dataVector, int iteration, double
distance, double radius)
The most interesting line of code in this method is actual accommodation:
neuronWghts[i] = neuronWghts[i] + learningRate * falloffRate *
(dataVector[i] – neuronWghts[i]);
(dataVector[i] – neuronWghts[i]);
Which stands for formula:
Why did I make all methods virtual and so much protected properties? That is intent of my next post on implementation of SOM, where I’m going to talk about Parallelization of calculations in our algorithm.
Self-Organizing Maps – Заженемо речі в гратку
March 20, 2010 KohonenAlgorithm, MasterDiploma 2 comments
Одним із хороших тестів Самоорганізаційної карти є двовимірна інтерпретація двовимірного вхідного простору. Нейрони нейромережі почитають заповняти той простір із якого приходять вхідні вектори, таким чином можна наочно спостерігати за тим чи нейромережа дає хороші результати.
Для цього я використав решітку розміру 10 на 10. Нейромережа була початково ініціалізована випадковими значеннями нейронів від 0.25 до 0.75. Таким чином якщо постійно вчити нейромережу випадковими значеннями (від 0 до 1), то гратка повинна “розвернутися” на всю площину.
Я використовую 500 кроків на кожному із яких проганяю 100 випадкових точок для того щоб згладити навчання.
Ініціалізація:

Перша ітерація:

Друга:

300:

Остання (500та):

Якщо вхідні значення подавати не із всієї множини X [0, 1], Y[0, 1], а із множини що займає певний об”єкт, то карта просто дуже легко впишеться в нього.
Щоб переконатися в цьому я використав силует дівчини і для навчання подавав тільки точки, які входили в площину, де знаходиться дівчина.

Зробити це для мене було, корисно, оскільки я таки знайшов недолугі частини моєї імплементації і виправив декілька помилок в алгоритмі. Надалі я можу спокійно працювати над паралелізацією обрахунків.
Я сподіваюся що вам сподобалося. Коментарі?
Possible Parallel Algorithm for Self-Organizing Maps
March 3, 2010 KohonenAlgorithm, MasterDiploma No comments
I already have some implementation of the parallelization in algorithm of SOM.
Let us quickly remind the main steps of the classical Kohonen learning algorithm.
- Initialization – means setting values to the network, either random or from input space.
- Sampling – select random vector x from the input space.
- Similarity matching – find best matching neuron, i.e. neuron which is most similar to the x.
- Update – need to update neighbourhood neurons to the BMN in particular radius r, which is decreasing with time.
- Continuation (2-5) – we repeat 2-5 many times, while do not have map with enough quality.
As you see algorithm could be very expensive if we have big amounts of data.
Also, steps 3 and 4 takes the most of time, what if we execute 2-3-5 in separate threads? Yes, we could do this to some extend. Main issue is when we have overlapping of affected area by two best matched neurons wich we found in separate threads.
I’m bit tired to write a lot of explanations of this algorithm, so I prepared 3 images that says for themselves. Hope will have detailed explanations and different tuning things for this soon.
Overlapping case, not good for parallelization

Free to go with two threads case

Master-Slave schema for algorithm

C# is language for my Diploma. It just won. What could I do?
February 21, 2010 C#, Java, MasterDiploma 2 comments
Today I committed initial version of my Diploma Work Sources.
And there are few interesting things regarding to my first commit.
Thing One (Language)
I re-wrote all my last year course work from Java to C#.
And I did it all in about 12 hours. Its just amazing how my developing speed differs in eclipse and Visual Studio IDEs. As I remember same took me 50+ hours with Java + eclipse and I did all without enthusiasm.
I hate writing properties in Java
This is one thing where I do think that Java is kind more verbose than C#. There are some others, like “var”, etc. Microsoft works on improving C# language.
C#
public double[] Parameters {get; set;}
Java
private double[] parameters;
public double[] getParamateres(){
return parameters;
}
public void setParamateres(){
return parameters;
}
How important is your knowledge of IDE?
I would say that even more then knowing of language. Nowadays most of the languages are object-oriented, they all have similar principles and ideas and code looks almost the same. If we talk about C# and Java they are extremely alike.
I’m not very familiar with Java, but I can write Java code easily and if there are some Java specific gaps I quickly fulfill them with google search.
But when we talk about my speed of coding in eclipse IDE – it is really outstanding thing where my capabilities suck.
Code refactoring tool
That is another thing that could significantly increase your productivity. I’m using Resharper 5.0 Beta. Having experience of using it, I can think about what I want to have, but not how to type that.
Live templates that generates me unit test method after I just type “test”. Delivering from interface, I just created, without typing class name. Moving initialization of fields to the class constructor with single command. “Alt+Enter” just thing instead of me in contest of where mouse cursor is located and proposes me decisions. — these all are things why I love Resharper. I wrote complex architecture with about 40 classes in about 12 hours. It generates what I think.
Thing Two (Architecture)
I improved my Self-Organizing Maps implementation architecture significantly. What is did is having all implemented in really decoupled interfaces. Main learning processor is just like preparing dinner. You just add component and you do have what you want.
public LearningProcessorBase(
ILearningData learningData,
INetwork network,
ITopology topology,
IMetricFunction metricFunction,
ILearningFactorFunction learningFactorFunction,
INeighbourhoodFunction neighbourhoodFunction,
int maxIterationsCount)
{
LearningData = learningData;
Network = network;
Topology = topology;
MetricFunction = metricFunction;
LearningFactorFunction = learningFactorFunction;
NeighbourhoodFunction = neighbourhoodFunction;
MaxIterationsCount = maxIterationsCount;
}
What is the benefit?
Now I’m able easily setup few dependency Profiles and experiment with them. So I can play with different activation, neigbourhood, metric and leaning factor functions, at the same time I can use different topologies like matrix and hexagonal.
Also learning process is now really encapsulated and to add Concurrency implementation should be easily.
Thing Three (I have same results with less effort)
To prove that I have same results I’ve used same application of my Kohonen Maps: classification of animals.
Here is input data list of different animals. Each row describes animal’s properties.

Here is result matrix:

Thing Four (Conclusion)
I’m really sorry that it is boring for me to have my Diploma written on Java. But I really think that my goal is to invent multi-threaded algorithm that could significantly improve SOM calculations. And I feel really comfortable with C#, so I can enjoy research work without spending time on convincing myself that I do need to accomplish all with Java.
But this doesn’t mean that I gave up with learning Java. No – I will continue implementing all GoF Design Patterns on this pretty language – see my table.
Lambda Expression or Simple Loop
February 20, 2010 .NET, LambdaExpression, MasterDiploma 6 comments
For my Diploma work I need to calculate distance between two vectors.
For example, Euclidean distance is calculated like:

How could it look if I do have two lists with values?
Something like this:
public double GetDistance(IList<double> firstVector, IList<double> secondVector)
{
double sum = 0;
for (int i = 0; i < firstVector.Count; i++)
{
sum += (firstVector[i] – secondVector[i]) * (firstVector[i] – secondVector[i]);
}
return Math.Sqrt(sum);
But, please take a look how sweet this all could be with Lambda Expression:
public double GetDistance(IList<double> firstVector, IList<double> secondVector)
{
double sum = firstVector.Select((x, i) => (x – secondVector[i]) * (x – secondVector[i])).Sum();
return Math.Sqrt(sum);
}
Of course main point of this post is not to show all beauty of LE, but either what did happen after I wrote this Lambda expression. Maniacal interest in what is faster to execute and what is the difference in performance of this two methods appeared in my mind, so I prepared few simple tests.
I’ve ran my tests on 1000000 elements and results were such:
- Lambda expressions are quite slower than simple loops.
- My test showed that primitive loop is faster in about 15-20%.
Also, I played with VS performance analyzer (Analyze -> Launch Performance Wizard…).
It allows me run one version of code (Lambda) and get detailed report, then run another version of code (Loop) and get another report. After that I’m able to compare results seeing performance improvements. So that is good tool.