February 22, 2026 AI, AI Agent, HowTo No comments
My 1-Hour Open Claw Setup: Docker, Llama 3.1, and Telegram
I saw all the fuss about Open Claw online and then spoke to a colleague and she was saying she is buying a Mac mini to run Open Claw locally. I could not resist the temptation to give it a try and see how far I can get. This post is just a quick documenting what I was able to do in like one hour of setup.
If you’re like me and find it difficult to follow all the latest AI hype and missed it, Open Claw is an open-source AI agent framework that connects large language models directly to your local machine, allowing them to execute commands and automate workflows right from your terminal or your phone.
A quick preview below. This is just nuts. In one hour I was able to run OpenClaw on Docker talking to llama3.1 running locally and communicating with this via Telegram bot from my phone 🤯.
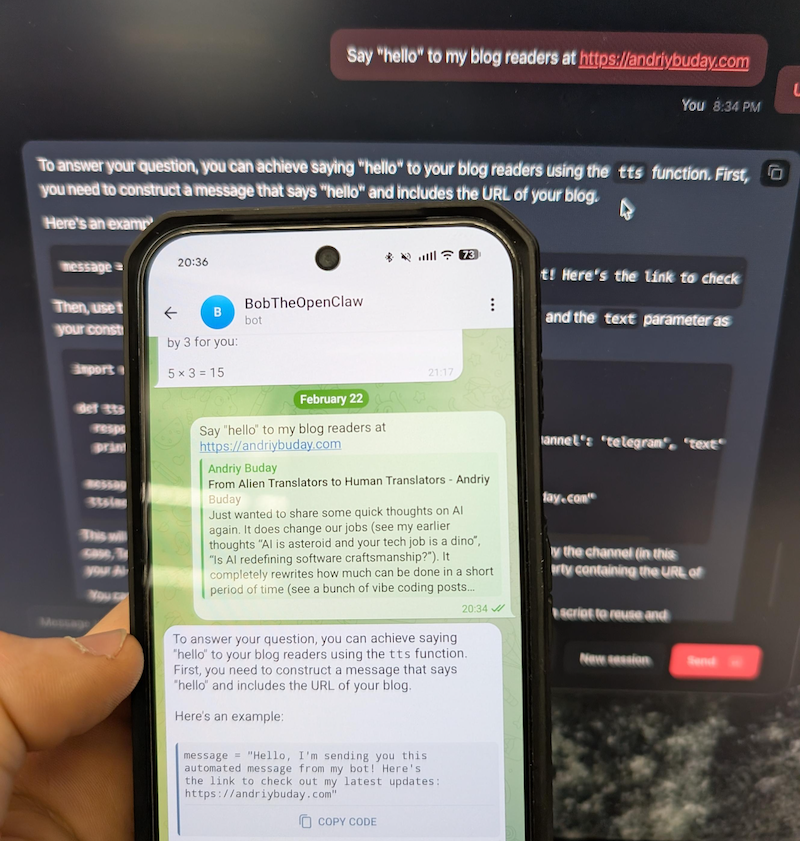
Back in the old days I would open some kind of documentation and follow steps one by one and unquestionably get stuck somewhere. This time I started with Gemini chat prompting it to guide me through the installation and configuration process. This proved to be the best and quickest way.
Decision 1: Running locally or in some isolation.
I think this one is an obvious choice. Giving hallucinating LLMs permission to modify files on my primary laptop sounds like a recipe for disaster. Decided to go with Docker container but if I find the right workflows I might buy Mac mini as well.
Commands were fairly simple, something along these lines:
git clone https://github.com/openclaw/openclaw.git
cd openclaw
./docker-setup.sh
docker compose up -d openclaw-gateway
Decision 2: Local LLM or Connect to something (Gemini, OpenAI)
This is a more difficult decision to make. Even though I’m running an M4 with 32GB, I cannot run too large of a model. From reading online it is obvious that connecting to large LLMs has an advantage of not hallucinating and giving best results but at the same time you’ve got to share your info with it and run the risk of running into huge bills on token usage. Since this was purely for my self learning and I don’t yet have good workflows to run, I just decided to connect using a small model llama.3.1 running via Ollama. Since it was running on my local machine and not docker, I had to play a bit with configuration files but it worked just fine. And yeah, the answers I would get are really silly.
Later I found that ClawRouter is the best path forward. Basically you use a combination of locally run LLM and large LLMs you connect to. I might do this in the next iteration.
Decision 3: Skills, Tools, Workflows
This is just insane how many things are available. Because this can run any bash (yeah, in your telegram you can say “/bash rm x.files” – scary as hell) on the local the capabilities for automation with LLMs are almost limitless.
Conclusion
I can barely keep up with all of the innovations that are happening in the AI space but they are awesome and I’m inspired by the people who build them and feel like I want to vibe code so much more instead of spending my time filling-in my complex cross-border tax forms over the weekend.
Level Up Your Work: Why Documenting Everything Matters
September 28, 2024 HowTo, Opinion No comments
If you are in a knowledge job, do yourself a favor and document everything as if your activities and thoughts were relentlessly producing logs similarly to a production server. Make it a habit and develop it so it becomes second nature. Offload cognitive burden to your computer, you don’t need and won’t be able to hold all of that information in your brain.
Let me give some of my personal examples and then follow up with how this was useful to me and others.

1:1 meetings
We all have 1:1 meetings: with our managers, peers, other stakeholders. I have a running doc for each individual person and take notes of every work conversation. For every person I create a go-link (something like go/person-andriy). This helps in 3 different ways:
- Adding topics. Every time I think about a topic to discuss with someone it is basically very keystrokes away. never have to go over the mental struggle of “Oh, what was that thing I had to talk to them about?”
- Searching for info. This one is probably obvious, but just to emphasize, I think our memories work by association, and it is often easier to look up something if you have a person in mind for a specific topic.
“Talk to X” docs
I extended this practice of storing topics for conversations into my personal life. I’m usually not documenting conversations themselves as they happen over coffee or walk and it would have been super weird to type during those. At the same time those docs work as a quick refresher and I found that in most cases this hugely enriches my conversations.
Cross-referencing everything
Cross-reference! cross-reference! When writing documents we obviously reference the sources of information, but a step further is to also do it in reverse (if possible). This helps connect the information and traverse it in any direction. So, if there was a strategy created based on a dozen of discussions with multiple teams, adding a link to that strategy to each discussion’s document will help each team relate to what that discussion has led to.
Documenting before and after religiously
A new practice I picked at Google is to capture “Landed Impact” in the design document after the actual launch. A design document would normally have effort justification, which often includes expected impact, but then “Landed Impact” would capture what actually happened. And I keep adding to that section. As a very specific example, I finished a project that reduces the monetary impact of outages a couple of years ago, and relatively recently there was an outage that would have cost us a lot more money if that project wasn’t done. I simply went to that old doc and documented this more recent impact. Why spend effort on this? Here we go:
Artifacts pay off
Presence of good artifacts makes a huge and oftentimes decisive difference to the outcomes of performance reviews and promo discussions. Think about the promotion process, you cannot even imagine how the presence of solid artifacts is important. With the artifacts in place people don’t have questions, they are like “here is the impact, here is leadership, this is influence, SOLID case”. Instead if artifacts are sloppy it becomes hard to drive conclusions from them, people are like “scope of work is unclear, impact might not be for the next level”. With good artifacts you are offloading cognitive load not just for yourself but for others, you make their decision process easier and they also feel like their responsibility is taken care of.
Unfinished work
Do you know those dreadful situations when a project is axed? This could be in your control (you didn’t find enough impact in work) or outside of your control (reorgs made this part of thing irrelevant, it is too late to market). Are a few months of your effort all waste? Nope, if you documented the learnings, basically you have your retrospective and learnings document ready. You hand it over to leadership and they can use it as a clear case of work being done. A quick failure is also ok as long as there is learning from it and how do you know if there was learning if there is nothing in the end?
Tooling
Does tooling matter? Well, someone could argue that it doesn’t as long as it does the job, but I’m yet to find any tool that works as well as Google docs: it is accessible everywhere you log in, searchable, shareable, collaborative. Works well at work and works well for personal things. Even this blog post originated in a Google Doc. And, yes, I tried other tools.
Conclusion
Same as the introduction: do yourself a favor and document everything as if your activities and thoughts were relentlessly producing logs. Offload cognitive overhead to docs and make your brain busy with now.
Favorite Debugging Strategies
September 22, 2024 Debugging, HowTo No comments
This is original content by Andriy Buday.

I just wanted to document a few different strategies for debugging and root-causing issues that have worked for me in the past, with examples. Two things about this post: it isn’t an attempt to provide a holistic view on debugging, mainly because there are plenty of articles out there. Also, I recently tried using an LLM with a relatively simple prompt, and it generated quite an impressive summary. Instead, I wanted to share a few examples and just a few approaches I like. I have two or three favorite strategies for debugging:
Time & changes
In my experience, if something worked and then stopped more likely than not a change was introduced recently, this is why there is a concept of “change management”. Simply looking at anything that changed at the same time when the problem appeared helps. Steps:
- Identify the time of when the problem first started.
- Collect available symptom information, such as error messages.
- Lookup relevant codebases, releases, data and config changes by the timestamp. Prioritize search using clues from sympthoms but don’t skip lookup just because it seems less relevant.
Sometimes an error message could give a straightforward path to identifying an issue. Happy scenario could look like this: you find the error message in the codebase, open the file change history and right there you see a problematic change. But things aren’t always as straightforward.
Because a symptom can be at the end of a long chain of events I don’t always focus just on the clues from the symptom, but rather advise to look at anything unusual starting at the same time.
As an example, I was involved in root causing an issue where our server jobs were crashing and could not startup after the crash. After looking through logs it seemed something made them not able to load a piece of configuration data, so we looked at stack traces of the crash but it wasn’t bringing us any closer to solving the issue. Instead, by looking at logs at healthy servers we noticed non-critical warnings and inconsistency in configuration. These two things seemed unrelated but they started appearing around the same time, so by looking at logs at healthy servers we identified the fix.
As another example, a colleague of mine was investigating an issue when an API was crashing at specific type of requests, by looking at the changes to the API he couldn’t see any changes around the time of when this started happening. I suggested we expand our search, and see if other clients of this API had any changes and what we found was that someone updated all of the clients of the API at the timestamp of when we started to see the issue, but they forgot to update our client.
Isolation and Bisection
My next best favorite approach to debugging is reduction in the universe of possibilities. What can be better than halving it every time?
I found this approach to be the best when debugging a bunch of recently written code. If this is the code you have locally, you can simply split it into smaller chunks (like commenting out half of a function). If you pulled recent changes by other engineers, a strategy could be to sync to a version midway between your original base and the most recent changes. I have applied this so many times it feels natural.
As an example, we perform huge number of experimentation at Google, occasionally these experiments cause issues, starting from server crashes or impact on revenue in which case automatic systems normally kick in and disable culprit experiments, but sometimes things are more subtle and a culprit has be found semi-manually in a new batch of experiments, in which case we apply bisection strategy.
Rubber duck debugging
Yeah, you’ve read that right, google it after you finish with this post. Rubber duck debugging is a technique of articulating your problem to someone else, explaining what research has been done so far and what you are solving. Oftentimes, this results in an “aha” moment and a realization where the problem is. Since you don’t need too much involvement from another party other than listening, you can just talk to an actual rubber duck.
As a story, I once told about rubber duck debugging to a manager of a team of consultants with whom I worked, the next day he bought all of us rubber ducks. It was a very nice gesture.
But a bit more seriously, there is a lot of merit to this strategy. I have joined dozens of small calls with other engineers where they tried to debug a problem and when after explaining the issue to me and myself just asking them simple “why?”, “give me more details” questions at some point they realized where the problem was. All of this without me even understanding their code or what they are doing.
Other strategies
As I mentioned, I didn’t attempt to write a holistic overview of debugging strategies. Other things that worked for me were: using debugger (obviously), profilers, other tools, stack tracing top to bottom and bottom to top, logging more things, etc, etc. There simply are so many ways to diagnosing and root causing a problem and not all strategies are equally applicable.
What else worked great for you?
How to add Microsoft.Extensions.DependencyInjection to OWIN Self-Hosted WebApi
I could not find an example showing how to use Microsoft.Extensions.DependencyInjection as IoC in OWIN Self-Hosted WebApi, as a result here is this blog post.
Let’s imagine that you have WebApi that you intend to Self-Host using OWIN. This is fairly easy to do. All you will need to do is to use Microsoft.Owin.Hosting.WebApp.Start method and then have a bit of configuration on IAppBuilder (check out ServiceHost.cs and WebApiStartup.cs in the gist below).
It becomes a bit more complicated when you want to use an IoC container, as OWIN’s implementation takes care of creating Controller instances. To use another container you will need to tell the configuration to use implementation of IDependencyResolver (see WebApiStartup.cs and DefaultDependencyResolver.cs). DefaultDependencyResolver.cs is a very simple implementation of the resolver.
In case you are wondering what Microsoft.Extensions.DependencyInjection is. It is nothing more than a lightweight DI abstractions and basic implementation (github page). It is currently used in ASP.NET Core and EF Core, but nothing prevents you from using it in “normal” .NET. You can integrate it with more feature-rich IoC frameworks. At the moment it looks like Autofac has the best integration and nice documentation in place. See OWIN integration.
Rest is just usual IoC clutter. See the gist
I hope this blog post helps you with integrating Microsoft.Extensions.DependencyInjection in WebApi hosted via OWIN.
Simple check for breaking Database changes using NUnit and T-SQL CHECKSUM_AGG
October 1, 2015 C#, HowTo, QuickTip, SQL No comments
Imagine that your database is being used by another system that directly reads data from few of the tables. I know this is not a good idea and I would not recommend anyone to do anything similar. Unfortunately developers often do what they don’t really want to do.
In this post I just want to document a very simple way of verifying that you are not removing or modifying tables and columns that are being used by someone else.
My solution is dumb unit tests that select table schema information for the list of tables and columns and then builds checksum that is finally compared to expected checksum.
I don’t pretend to sound like this somewhat dirty solution is a right way, but it is very quick to implement and effective way. Here is the implementation in C#:
In code above we verify that we are not removing or modifying few columns in tables Table1 and Table55, since they are used by SystemX. NUnit TestCase attributes are used to allow for multiple table checks. First parameter is a checksum that you would get for the first time by failing the unit test or by running query separately. Checksum calculation is simple but it has a bit of overburden with concatenating column names into one string and then parsing it again into a temp table for the “IN” condition. (Of course there are other ways, but I find this one to be a bit less code). Also it probably worth to mention that we apply database changes using FluentMigrator, so tracking what exactly was changed that caused particular Unit Test case to fail would be just to have a look at the latest commit.
I think this is acceptable solution for a small set of checks. Probably you need another solution if your database is heavily used by another systems.
Hopefully is helpful to someone. At least I write this post to have it handy for myself in case I need something similar done quickly.
Backup and Restore. Story and thoughts
April 7, 2014 HowTo, Opinion No comments
Usually when I have some adventures with backing-up and restoring I don’t write a blog post about that. But this time it was bit special. I unintentionally repartitioned external drive where I kept all of my system backups and large media files. This made me rethink my backup/restore strategy.
The story
I will begin with the story of my adventures. Currently I’m running Windows 8.1. The other evening I decided I want to play old game from my school days. Since I couldn’t find it I decided to play newer version still relatively old – released in 2006. As usual with old games and current OSs it wouldn’t start. As it is normal for programmer I didn’t give up. First of all there was something with DirectX. It was complaining that I need newer version, which I of course had, but it was way too new for the game to understand. After fixing it game still wouldn’t start because of other problems. I have changed few files in system32. It still didn’t help. Then I decided on other approach – installing WinXP on virtual machine and run it there. I did it with VirtualBox and it didn’t work because of some other issues. Then I found Win7 virtual machine I used before for VMware, but that VM didn’t want to start.
At this point I decided to give up with that game. So to compensate I started looking for small game I played in university. Unfortunately the other game also didn’t want to start by freezing my PC. After reboot… ah… actually there was no reboot since my Windows made its mind not to boot any longer!
Now I had to restore. Thankfully my Dell laptop had recovery boot partition and I was able to quickly restore to previous point in time. Not sure why Windows didn’t boot if recovery wasn’t pain at all.
After that happened I decided that I need additional restoring power. So I ran program by Dell called “Backup and Recovery” to create yet another backup of the system. Program asked me for drive and I found one free on my external HDD where I keep system images. Unfortunately I didn’t pay attention to care about what that special backup might do. It created bootable partition and of course repartitioned entire drive. I pulled USB cable when I realized what it started to do!
I had to recover again, but now files on repartitioned drive. If you look online there are some good programs that allow you to restore your deleted files and even find lost partitions. One of such is EaseUS, but it costs money and I didn’t want to pay for one time. Thus I found one free called “Find And Mount” that allows to find lost partition and mount it as another drive so I can copy files over. That’s good but for some reason speed of recovery was only 512Kbit/s so you can imagine how much time it would take to recover 2TB of stuff. I proceeded with restoring only the most important stuff. Maybe in total restoring took like 30+ hours.
Bit more on this story. Since I needed to restore so much stuff I didn’t have space for it. My laptop is only 256Gb SSD and my wife’s laptop (formerly mine) also has only that much. But I had 512 HDD left aside. So I just bought HDD external drive case for some 13 EUR and thus got some additional space.
So that was end of story. Now I want to document what I do and want to start doing in addition to be on the safe side.
Backup strategy
What’s are the top most important files not to lose? – These are photos and other things that are strongly personal. I’m pretty sure if you have some work projects they are already under source control or handled by other parties and responsible people. So work stuff is therefor less critical.
My idea is that your most important things should be just spread as much as possible. This is true for photos I have. They are just on every hard drive I ever had. At least 5 in Ukraine and 4 here in Austria. Older photos are also on multiple DVDs and CDs. Some photos are in Picasa – I’m still running old offer from Google 20Gb just for 4$ per year. All phone photos are automatically uploaded to OneDrive with 8Gb there. Also I used to have 100Gb on DropBox but then I found it too expensive so stopped keeping photos there.
All my personal projects and things I created on my own are treated almost the same as photos, only they are not so public, often encrypted.
So roughly backup strategy:
- Photos and personal – as many copies as possible and at as many physical places as possible, including cloud storages
- System and all other – System Images and bootable drive, including usage of “File History” feature in Windows 8.1
I started to think if I want to buy NAS and some more Cloud. For now will see if I can get myself into a trouble again and what it would cost if it happens.
On the image below Disk 0 is my laptop’s disk. Disk 1 is where I now have complete images of 2 laptops at home, complete copy of Disk 2 and also Media junk. Disk 2 is another drive with Windows installed, which will now be used regularly for backups and for “File History”.

Now some links and how-to info:
- Find and Mount application for restoring partitions
- EaseUS application with lots of recovery options, but costs money
- Enabling “File History” and creating System Image in Win8.1 can be done from here: Control PanelSystem and SecurityFile History
- External USB 3.0 HDD 2.5’’ Case I bought
- Total Commander has features to find duplicate files, synchronize dirs and many other which come handy when handling mess after spreading too many copies around
This was just a story to share with you but it emphasises one more time that backups are important.
P.S. I finally managed to play newer version of 2nd game :)
Application Fabric Cache – an easy, but solid start
I would like to share some experiences of working with Microsoft AppFabric Cache for Windows Server.
AppFabricCache is distributed cache solution from Microsoft. It has very simple API and would take you 10-20 minutes to start playing with. As I worked with it for about one month I would say that product itself is very good, but probably not enough mature. There are couple of common problems and I would like to share those. But before let’s get started!
If distributed cache concept is something new for you, don’t be scary. It is quite simple. For example, you’ve got some data in your database, and you have web service on top of it which is frequently accessed. Under high load you would decide to run many web instances of your project to scale up. But at some point of time database will become your bottleneck, so as solution you will add caching mechanism on the back-end of those services. You would want same cached objects to be available on each of the web instances for that you might want to copy them to different servers for short latency & high availability. So that’s it, you came up with distributed cache solution. Instead of writing your own you can leverage one of the existing.
Install
You can easily download AppFabricCache from here. Or install it with Web Platform Installer.
Installation process is straight forward. If you installing it to just try, I wouldn’t even go for SQL server provider, but rather use XML provider and choose some local shared folder for it. (Provider is underlying persistent storage as far as I understand it.)
After installation you should get additional PowerShell console called “Caching Administration Windows PowerShell”.
So you can start your cache using: “Start-CacheCluster” command.
Alternatively you can install AppFabric Caching Amin Tool from CodePlex, which would allow you easily do lot of things though the UI. It will show PowerShell output, so you can learn commands from there as well.

Usually you would want to create named cache. I created NamedCacheForBlog, as can be seen above.
Simple Application
Let’s now create simple application. You would need to add couple of references:

Add some configuration to your app/web.config
<section name="dataCacheClient" type="Microsoft.ApplicationServer.Caching.DataCacheClientSection, Microsoft.ApplicationServer.Caching.Core" allowLocation="true" allowDefinition="Everywhere"/> <!-- and then somewhere in configuration... --> <dataCacheClient requestTimeout="5000" channelOpenTimeout="10000" maxConnectionsToServer="20"> <localCache isEnabled="true" sync="TimeoutBased" ttlValue="300" objectCount="10000"/> <hosts> <!--Local app fabric cache--> <host name="localhost" cachePort="22233"/> <!-- In real world it could be something like this: <host name="service1" cachePort="22233"/> <host name="service2" cachePort="22233"/> <host name="service3" cachePort="22233"/> --> </hosts> <transportProperties connectionBufferSize="131072" maxBufferPoolSize="268435456" maxBufferSize="134217728" maxOutputDelay="2" channelInitializationTimeout="60000" receiveTimeout="600000"/> </dataCacheClient>
Note, that above configuration is not the minimal one, but rather more realistic and sensible. If you are about to use AppFabric Cache in production I definitely recommend you to read this MSDN page carefully.
Now you need to get DataCache object and use it. Minimalistic, but wrong, way of doing it would be:
public DataCache GetDataCacheMinimalistic() { var factory = new DataCacheFactory(); return factory.GetCache("NamedCacheForBlog"); }
Above code would read configuration from config and return you DataCache object.
Using DataCache is extremely easy:
object blogPostGoesToCache; string blogPostId; dataCache.Add(blogPostId, blogPostGoesToCache); var blogPostFromCache = dataCache.Get(blogPostId); object updatedBlogPost; dataCache.Put(blogPostId, updatedBlogPost);
DataCache Wrapper/Utility
In real world you would probably write some wrapper over DataCache or create some Utility class. There are couple of reasons for this. First of all DataCacheFactory instance creation is very expensive, so it is better to keep one. Another obvious reason is much more flexibility over what you can do in case of failures and in general. And this is very important. Turns out that AppFabricCache is not extremely stable and can be easily impacted. One of the workarounds is to write some “re-try” mechanism, so if your wrapping method fails you retry (immediately or after X ms).
Here is how I would write initialization code:
private DataCacheFactory _dataCacheFactory; private DataCache _dataCache; private DataCache DataCache { get { if (_dataCache == null) { InitDataCache(); } return _dataCache; } set { _dataCache = value; } } private bool InitDataCache() { try { // We try to avoid creating many DataCacheFactory-ies if (_dataCacheFactory == null) { // Disable tracing to avoid informational/verbose messages DataCacheClientLogManager.ChangeLogLevel(TraceLevel.Off); // Use configuration from the application configuration file _dataCacheFactory = new DataCacheFactory(); } DataCache = _dataCacheFactory.GetCache("NamedCacheForBlog"); return true; } catch (DataCacheException) { _dataCache = null; throw; } }
DataCache property is not exposed, instead it is used in wrapping methods:
public void Put(string key, object value, TimeSpan ttl) { try { DataCache.Put(key, value, ttl); } catch (DataCacheException ex) { ReTryDataCacheOperation(() => DataCache.Put(key, value, ttl), ex); } }
ReTryDataCacheOperation performs retry logic I mentioned before:
private object ReTryDataCacheOperation(Func<object> dataCacheOperation, DataCacheException prevException) { try { // We add retry, as it may happen, // that AppFabric cache is temporary unavailable: // See: http://msdn.microsoft.com/en-us/library/ff637716.aspx // Maybe adding more checks like: prevException.ErrorCode == DataCacheErrorCode.RetryLater // This ensures that once we access prop DataCache, new client will be generated _dataCache = null; Thread.Sleep(100); var result = dataCacheOperation.Invoke(); //We can add some logging here, notifying that retry succeeded return result; } catch (DataCacheException) { _dataCache = null; throw; } }
You can go further and improve retry logic to allow for many retries and different intervals between retries and then put all that stuff into configuration.
RetryLater
So, why the hell all this retry logic is needed?
Well, when you open MSDN page for AppFabric Common Exceptions be sure RetryLater is the most common one. To know what exactly happened you need to verify ErrorCode.
So far I’ve see this sub-errors of the RetryLater:
There was a contention on the store. – This one is quite frequent one. Could happen when someone is playing some concurrent mess with cache. Problem is that any client can affect the whole cluster.
The connection was terminated, possibly due to server or network problems or serialized Object size is greater than MaxBufferSize on server. Result of the request is unknown. – This usually has nothing to do with object size. Even if configuration is correct and you save small objects you can still get this error. Retry mechanism is good for this one.
One or more specified cache servers are unavailable, which could be caused by busy network or servers. – Have no idea how frequent this one could be, but it can happen.
No specific SubStatus. – Amazing one!
Conclusion
AppFabricCache is very nice distributed cache solution from Microsoft. It has a lot of features. Of course not described here, as you can read it elsewhere, say here. But to be able to go live with it you should be ready for AppFabricCache not being extremely stable & reliable, so you better put some retry mechanisms in place.
To be honest if I was one to make decision if to use this dcache, I would go for another one. But who knows, maybe other are not much better… I’ve never tried other distributed caches.
Links
Thank you, and hope this is of some help.
WP7 Mango and NUnit from console
October 22, 2011 HowTo, NUnit, UnitTesting, WP7 3 comments
If you are building Windows Phone application you probably have faced… well… not rich support for unit testing. But of course there is one rescuing thing – WP7 is almost the same Silverlight application. Thus you have wider area to search for solution. Awesome… but I wouldn’t write this blog post if everything is that easy. Right?
Support for NUnit and command line
Microsoft for some reason doesn’t care about huge community of those who use NUnit for their projects, and believe me not for small projects. So there of course is mstest project template that allows you to run tests inside of the appropriate CLR. There is good Silverlight Unit Tests Framework and here is information on how you can cheat in order to get it working for the phone. Problem with these two frameworks is obvious – they are not supporting console – they run in native for Silverlight environment – either on phone or in web. See pictures (phone and web respectively):


I know that there are ways to make it happen from console under (msbuild for example this temporary wp7ci project on codeplex). Hold on… one second. Again something very specific to Microsoft – msbuild. But what if I’m using nAnt?
Of course there is port of the NUnit for the Silverlight (here is how), also you can change tests provider in the “Silverlight Unit Tests Framework” (further SUTF).
Nevertheless summary is simple – no support for running nunit tests for the WP7 from command line.
Support for command line – solution
I came up with odd solution to force nunit-console to run unit tests in command line. After I observed it crashing with error TargetFrameworkAttribute I reflected mscorlib and googled a bit to discover this attribute exists in mscorlib of 2.0.5.0 version, but nunit actually targets 2.0.0.0 one (.net 2.0). Thus I decided to download sources of NUnit and recompiled those against .net framework 4.0 (mscorlib 2.0.5.0). Reason for this error is that Silverlight also uses higher version of mscorlib.
Awaiting for NUnit 3.0 which is promising to have support for Silverlight.
Support for Mango – problem
Before upgrading to Mango our tests for WP7 were created by testDriven (to be honest – it is what they use inside of their SUTF). We didn’t have support for command line and tests were running only because they are so Silverlight compatible.
With updating to Mango everything just died. Tests projects simply didn’t get loaded into solution. With this message:

“Not a big deal” you say. Actually a big deal, because you can get rid of this message by editing project files to have target framework profile set to WP71 and to reference only WP71 assemblies. But in this case you lose all of you compatibility with Silverlight and when you run your tests you start to get weirdest exceptions in the world like this one below:
System.DivideByZeroException : Attempted to divide by zero.
at System.Collections.ObjectModel.ObservableCollection`1..ctor()
At least this brings some more sense:
System.InvalidProgramException : Common Language Runtime detected an invalid program.
Support for Mango – solution
Solution I came up with is not 100% right, but at least it works. I just had to pretend that I’m still completely compatible with Silverlight. So I created copy of my project. One is considered to be used from command line and other for usage from VS.
Project 1 is used under VS has correct references directly to WP71 assemblies, like below:
<Reference Include="System.Windows">
<HintPath>..LibrarySilverlightWP71ReferencesSystem.Windows.dll</HintPath>
</Reference>
This ensure that VS loads your projects without errors, also you make it think it is WP7 by these:
<TargetFrameworkProfile>WindowsPhone71</TargetFrameworkProfile>
and this:
<Import Project="$(MSBuildExtensionsPath)MicrosoftSilverlight for Phone$(TargetFrameworkVersion)Microsoft.Silverlight.$(TargetFrameworkProfile).Overrides.targets" />
<Import Project="$(MSBuildExtensionsPath)MicrosoftSilverlight for Phone$(TargetFrameworkVersion)Microsoft.Silverlight.CSharp.targets" />
Project 2 is used for console and is pretended to be pure Silverlight, so it has:
<Reference Include="System.Windows">
<Private>True</Private>
</Reference>
Which in reality copies (because of <Private>) wrong assemblies – from Silverlight, not from phone.
You would need to play a lot with which assemblies you want to get in folder where you run tests. I do have some confidence that Silverlight and WP7 are much compatible thanks to this brilliant explanation of what is WP7 from developer’s view.
Results

At #1186 I finally got build working and running tests. At #1193 I invented this Silverlight pretending trick. And finally till build number #1196 I ignored couple of incompatible tests and fixed some really failing tests.
Hope this helps someone. At least it is going to help my team.
Using Distributed Transactions in multitier environment
February 28, 2011 HowTo No comments
In one of my previous posts I wrote that we use Distributed Transactions in our code. This worked just fine till we tested all installed on one machine. But once we installed SQL server on machine1 and our services on machine2 and services that use our services on machine3 we got following error messages:
“Inner exception message: Network access for Distributed Transaction Manager (MSDTC) has been disabled. Please enable DTC for network access in the security configuration for MSDTC using the Component Services Administrative tool.”
This means that your transaction is distributed but not as much as you wish it to be. So it is not enabled for Network access. You would need to go to Administrative Tools –> Component Services to enable it.

Here is everything explained up and down how you Enable Network DTC Access:
http://msdn.microsoft.com/en-us/library/cc753510%28v=ws.10%29.aspx
Also, please keep in mind that you would need to enable it on both machines between which you are distributing your transaction.
.NET Remoting Quickly
August 11, 2010 .NET, C#, HowTo No comments
As you may know recently I got junior to mentor him. In order to understand his capabilities and knowledge I asked him to do couple of things, like explain me one Design Pattern he knows, explain SCRUM and write the simplest .NET Remoting. So that was yesterday and today I verified that he failed with .NET Remoting, but it doesn’t mean that he is bad. He just need learn googling art more. I asked that for next day, and gave him stored procedure to write. Hope he will be smart enough to finish it till I come tomorrow from my English classes.
.NET Remoting
To ensure that I’m not asshole that asks people to do what I cannot do, I decided to write it by my own and see how long will it take for me. It took me 23 minutes. Hm… too much, but I should complain at VS about “Add Reference” dialog.
So here we have three projects in Visual Studio: one for Server, one for Client and of course Proxy class shared between client and server.

Shared proxy class ChatSender in ChatProxy assembly:
public class ChatSender : MarshalByRefObject
{
public void SendMessage(string sender, string message)
{
Console.WriteLine(string.Format(“{0}: {1}”, sender, message));
}
}
Server (ChatServer):
class Program
{
static void Main(string[] args)
{
var channel = new TcpServerChannel(7777);
ChannelServices.RegisterChannel(channel, true);
RemotingConfiguration.RegisterWellKnownServiceType(typeof(ChatSender),
“ChatSender”, WellKnownObjectMode.Singleton );
Console.WriteLine(“Server is started… Press ENTER to exit”);
Console.ReadLine();
}
}
Client (ChatClient assembly):
class Program
{
static void Main(string[] args)
{
Console.WriteLine(“Client is started…”);
ChannelServices.RegisterChannel(new TcpClientChannel(), true);
var chatSender =
(ChatSender)Activator.GetObject(typeof(ChatSender), “tcp://localhost:7777/ChatSender”);
string message;
while ((message = Console.ReadLine()) != string.Empty)
{
chatSender.SendMessage(“Andriy”, message);
}
}
}
My results

