October 11, 2025 AI, Fun 2 comments
Vibe Coding & Designing Typing Multiplayer Game
The other day my daughter showed me the typing game her teacher encouraged kids to play. My daughter was impressed with my typing speed. This blog post is to impress her even more.
The game she played was online typing practice – you type text and compete with other players for speed and accuracy. Players are represented as racing cars. If you win races you qualify to higher league of players. In this post I want to do few things:
- Vibe code standalone JS file – you can try it out right in this blog post.
- Vibe design a full fledged online game.
- Vibe implement the backend for the multiplayer game.
Vibe Coding Typing Trainer
Here is the result of about 30 minutes of work. You can play it yourself (if reading from e-mail you may need to open the blog).
This was achieved with 13 prompts, summarized like this:
1. Initial project creation prompt
2. CORS issue fix request
3. Container class addition request
4. HTML demo update request
5. Simple version (typing.html) request
6. Visual version creation request
7. Error display duration adjustment
8. Error display fix attempt
9. Revert request for error display
10. UI enhancement with "click to activate" label
11. Visual version adjustment request
12. Final revert request
13. History documentation requestVibe Designing Multiplayer Game
Now instead of working with Claude, I started working with Gemini to create a design for the multiplayer game.
Here is the high level system design document: opens in another page.

Given that I explicitly prompted it to be fully stateless, relying only on client side local history, no login and no other complications this seems to be a fairly good start. My prompt was:
Now I want you to create a comprehensive system design to build the game described above. We need:
- simple website with JS logic
- backend that can create rooms of gamers based on their levels
- the game should protect user privacy so there is no user info stored on backend
- game history is only stored as long as user has local cookies
- backend should handle at least 10k users
- single game has max 6 players
- if user wins the game they are placed into higher leagueAs a next step I fed the generated system design document back to Claude in Visual Code. This time I had to fight a lot more with the AI as it was running into issues connecting players but finally arrived at the multiplayer game:

Prompting history:
- Initial setup of multiplayer backend server
- Setup Node.js with Socket.IO and databases
- Create basic server structure
- Implementation of matchmaking system
- Create skill-based queue system
- Handle player matching logic
- Game room and state management
- Implement room creation and management
- Handle player synchronization
- Create typing texts table
- Add sample data
- Visual keyboard integration
- Add keyboard visualization to multiplayer version
- Implement key highlighting
The backend is powered by:
- Node.js
- Socket.IO (for real-time WebSocket communication)
- Redis (for server-side data/caching)
- PostgreSQL (for the database)Conclusion
I have complete confidence that if I had 2 or 3 days to spend on this I could actually create a game that can be put out there on some servers and be actually playable by actual human beings! The new world of AI is nuts. I’m out of my time allocated to blogging, but I’m convinced over and over again, that the old times of programming are over – the only way to survive is to adopt.
P.S. Another thought: I have a friend who works on Linux kernel stuff. You would imagine that hardcore stuff like that would not be affected by the era of AI, but no, he says that AI helps to properly review pull requests to the kernel and catch real issues, moreover it does help to build more complex things. Caveat, of course, is that the proper knowledge is still required. Who knows, if I knew nothing about programming, maybe, I wouldn’t be able to build this typing game so quickly? Or, maybe, this is just a matter of time?
Finding Your Voice at Work
October 5, 2025 Opinion, RandomThoughts No comments
“If you stay silent as a mouse you will just stay where you are.“

This was the advice I got from a team lead at my first job, right after I’d rushed through the office to complain about a broken system that endangered a delivery to our client the next week. He praised me and didn’t want to shut me down, even if I might have overdone it. For many of us, finding that voice is the hardest part. We hold back our ideas, questions, and concerns for a number of reasons. Let’s break down the four most common ones:
- We assume that something is obvious.
- We assume that others know better.
- Deference to authority.
- Physiological: not feeling safe, fear of judgement.
Stating the Obvious
One of the biggest mistakes we make is assuming that others have the same knowledge or perspective as we do. What seems obvious to you is often the result of your unique experiences, learning, and context. But others may not have the same background.
One of my university professors used to say there are only three types of proof: by contradiction, by reasoning, and obvious. I struggled with the 3rd one because when something is somehow “obvious”, it wasn’t that obvious to me at all.
Quickly re-stating that “obvious” part often removes the ambiguity from the discussion and sets the common baseline. Without being aligned on the same baseline the entire conversation doesn’t make sense, that’s why it is super-important to simply re-state the “obvious” and explicitly list what the assumptions are.
Sometimes I notice how very senior leaders would ask very basic questions about something only to witness that not everybody in the room was on the same page about this basic truth.
Sharing the “obvious” has very little drawback. While there may be a small cost, say a bit more document space or an extra minute in a meeting, that cost is a cheap insurance policy against catastrophic misalignment. A little information overhead is always better than massive miscommunication.
Others know Better
It is oftentimes true that others know better (to state the obvious). But this shouldn’t be a blocker, rather it should be an incentive! If you speak up and you’re wrong, you become the main beneficiary: you get corrected and learn a critical piece of information. If you’re silent, you leave the meeting still misinformed. If a question is forming in your mind, it’s highly likely that several other people in the room are thinking the exact same thing but are too afraid to ask. By asking, you don’t expose your ignorance; you serve the collective need for clarity.
Deference to Authority
Sometimes it’s not fear or lack of clarity, but simple deference to authority. When senior leaders are present, people instinctively stay quiet, assuming their ideas matter less or that others will take the lead. This one is tricky as it also includes some cultural aspects of how you were raised and also cultural aspects of your company.
More often than not, however, leaders actually want more people to speak. They value a challenging question or divergent perspective far more than a room full of nodding heads. In fact, leaders sometimes speak first precisely to kick-start the conversation, and they often intentionally hold back because they don’t want their presence to silence the room. In fact, sometimes leaders don’t speak at all precisely because they want to ensure others feel there is room to contribute. Silence out of deference is perceived as alignment, which can lead to misguided decisions. Don’t assume your idea matters less. Assume your perspective is a critical puzzle piece the decision-maker needs.
Physiological Safety
This one is a tough one because it’s rooted in our fundamental human desire for psychological safety. This is a need that is not always easy to satisfy in high-pressure environments, such as the big tech corporate world.
Google has done this famous study “Project Aristotle” which concluded that psychological safety was the number one predictor of a team’s effectiveness, more so than the individual skills, intelligence, or seniority of the team members. The “how” a team worked together was more important than the “who.” Safety there means that team members are confident that no one will embarrass or punish them for admitting a mistake, asking a question, or offering a new idea.
Being comfortable taking “interpersonal risks,” such as challenging the status quo, offering divergent ideas, or asking for help is a lot more beneficial than taking another risk of closing in and solving the problem on your own.
Conclusion
The path from “mouse” to “wolf” isn’t about aggression or volume. It’s about recognizing that your unique perspective is a crucial piece of the collective intelligence. Your job isn’t to be an expert on everything, but to ensure that the room has all the information it needs: whether that’s stating the obvious, asking the ‘dumb’ question, or challenging the senior leader. So:
Ask the ‘n00b’ question. Challenge the status quo. State the obvious. Share your ideas. You lose virtually nothing, but the collective clarity and your growth is a big win. Speak up!
Talk Is Cheap; The Smallest Code Change Speaks Loudest
September 28, 2025 Opinion No comments
How many times have you been in a meeting where a brilliant idea was discussed, only to have it disappear into thin air? “Talk is Cheap; Show me the code” by Linus Torvalds perfectly captures the frustration, which roughly means that ideas, promises, or arguments don’t carry much weight until they’re backed by action. In software, the ultimate proof is working code. To be brutally honest, I often talk more than I code, and while talking is important at more senior roles, the ultimate delivery is still code.

From “Wouldn’t It Be Nice” to “I Did It”
I have been in multiple discussions where we were talking about some tool or some product and we all thought, “oh, it would have been nice if the tool had this capability or just this extra command flag we can use”, but because none of us had familiarity with the tool it basically stayed with that “would have been nice”. Over time I noticed: diving into the code is usually less intimidating than it looks. Once you do, you not only solve the problem but also gain familiarity others don’t have.
Why don’t people do this more often? It’s simple: it requires effort taking time away from your main project and has a high risk of failure. My proposal is to time-box your effort. There is definitely a sweet spot where you can spend y hours on the thing, where uncertainty reduces the most drastically, to make the final call if more effort is worth it. The ‘y’ should be somewhat proportional but limiting to the benefit ‘x’ you get, maybe y = sqrt(x).
The Approval Stamp: Reducing Friction
Another example: I was using some internal tool and it had a simple UI validation bug. One path to take was to file a ticket with the team owning the tool, someone would look it up, which would definitely be low priority on their plate, and this would get fixed in few weeks or not at all, but I needed the fix right now to avoid workarounds, so I published the fix code change – literally 2 lines of code. It would have probably taken 2x more time to file the ticket and communicate with the tool owners. They only had to stamp the change.
A bit more abstract: let’s say you are using a system owned by someone else, and you need to change something from x to y. In one way you know that’s a simple change and the person is likely to agree, but explaining it and waiting for them to apply the change causes friction. Instead if you just do the change on your own, and getting Y instead of X is just an “approve” stamp on the other side you will get your stuff really soon.
How about Alignment?
But won’t you come across as someone for pushing for a change without aligning first? – Yup, there is such a risk. There is a very simple way to avoid this: just soften how you propose the change. Ideas: 1) give a quick short “heads-up” message “I have this idea to improve Z by changing x to y, I will share a preview change to show what I mean”; 2) frame your code change as a light proposal, a “preview”, a “suggestion”.
Conquering Uncertainty with Code
This is perhaps where the ‘smallest code change’ provides the most value. Many of us, myself included, can get lost in the abstraction of system design by drawing diagrams and talking through every possibility. While this is a necessary step, it’s not a substitute for engaging with the actual code. I’ve worked with software architects in the past who were so detached from the codebase that their designs were completely unworkable. They simply didn’t know what they were talking about. The solution is to complement your high-level design with ‘on the ground’ code.
The key learning for myself: whenever working on the design of something: do more code digging and make small refactorings along the way (even if a bit unrelated).
Feeling of Doing instead of Talking
This one is a bit subjective, but we are humans as well as software engineers. There’s a fundamental difference between talking about progress and actually making it. Pushing code feels a lot better than just talking about it. Wouldn’t you agree?
Next time you’re tempted to keep talking, try the smallest code change instead. It speaks louder than a hundred conversations. This is one lesson for me.
Conway’s Law Is Bi-Directional: How Teams Shape Systems and Systems Shape Teams
September 20, 2025 Opinion, TeamWork No comments
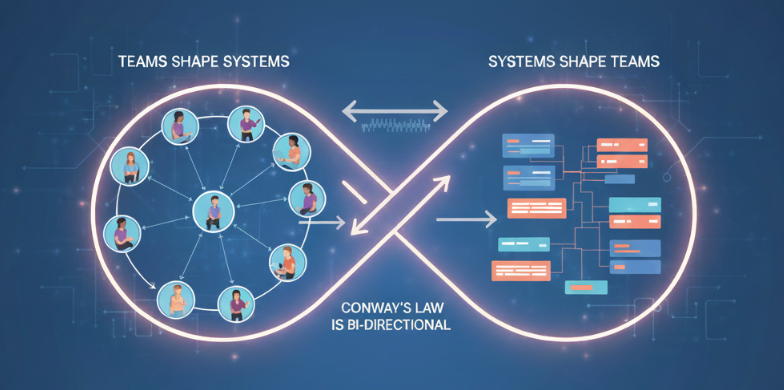
I once worked on a product where two Tech Leads couldn’t agree on direction. The result? Two different UIs for the same set of users. That’s Conway’s Law in action: systems mirrored organizational misalignment.
My personal observations over 17 years in large enterprise companies align with Conway’s. But I also believe this goes deeper. Causality runs both ways: organizations shape systems, and systems reshape organizations. In addition to this I think the technical problems the system is experiencing are reflections of communication dynamics.
Conway’s Law and Examples
A quick reminder of Conway’s Law: “Any organization that designs a system will produce a design whose structure is a copy of the organization’s communication structure.”. There are other variations of this. A simpler one I like to personally use in my conversations could be “Organizations design and build systems that mirror their own communication structure”.
For instance, if the company has extremely autonomous teams/orgs the company may end up in a situation where different systems are built with different tech stack and are fully decoupled but also hard to integrate if needed, but, let’s say if within an individual team/org communication is frequent and multi-directional their system might be tightly coupled and un-modular.
Direction of Causality: Org <=> System
So is it that once you have your organization you will end up with a particular system or is it while you build the system the organizational structure will simply organically mimic it?
That’s an important question and I’m of the opinion that this works both ways, meaning you can do re-orgs which will eventually lead to changes in technical aspects of the system, or you can make and push for design choices that over time will lead to org changes (like creating a team for a sub-module).
Companies sometimes deliberately reorganize teams or how they communicate (“Inverse Conway Maneuver”) to influence product architecture. This is one of the other reasons why re-orgs happen, but probably less frequently.
Take Amazon’s mandate for all of the internal teams to use AWS? I was on one of such teams and had to migrate some of our services to use AWS. This approach allowed Amazon to mimic external communication internally (external companies using AWS => internal teams using AWS). Internal engineers were both users and builders, so AWS could iterate quickly on real pain points. In this way feedback loop was that new communication channel that influenced how the systems evolved.
While Conway’s Law is usually stated as “organizations shape systems,” in practice I’ve seen a feedback loop. As soon as you draw a boundary in code, questions of ownership arise, and soon an organizational boundary emerges. Conversely, when leadership merges teams, systems often collapse back into monoliths or shared modules. Architecture creates new communication needs, which shape team structure, and team structure in turn reinforces or redefines architecture. This is why I argue causality is bi-directional: the system and the organization co-evolve.
When Communication Breaks Down
Communication bottlenecks eventually show up in code. Where teams don’t talk, APIs and integration points often become pain points. One team might be making assumptions about how the system behaves, they built their system based on that assumption and eventually operational issues show up. I personally observed this more frequently in micro-service based architectures, but monolithic systems are also susceptible to this.
Sometimes it takes introducing a liaison or two between two teams/orgs to fix things up. I have been working for one division at IAEA (UN) but was given to work on the project for another division, we were able to successfully integrate systems owned by two divisions. It is not so much just my contribution but rather a good decision to introduce new communication channels which resulted in changes to system integration.
Highly cross-functional teams often produce more rounded, cohesive, end-to-end systems. I’ve been on teams where many different roles were involved and worked very closely together (Meta seems to be very strong at this) as well as on teams where product management, database engineers were working in disconnected mode, producing outputs in sequence, which resulted in delays and systems that didn’t really do what they were supposed to.
Conclusion
Over and over I’ve observed mirroring between systems and communications structures, and I believe the causality is bi-directional, as such you can influence the system not just directly via design but by making organizational changes. The practical lesson is that you don’t always fix a broken system in the codebase alone. Sometimes the fastest path is changing how people talk, or who talks at all.
Vibe Coding AI that learns to play Snake game
September 14, 2025 AI, Uncategorized No comments
Today I’m Vibe Coding something and inviting you to follow along. This is not a very serious post. The purpose of this blog post is just to see how quickly we can build a NN that plays snake game and if we can improve it:

Steps we we will follow:
- Generating simplest snake game you can play with WASD keys.
- Generating AI that learns to play and watch it play.
- Attempt to improve generated code so it reaches better scores.
Step 1: Generating simplest snake game you can play
Obviously, I need to write a prompt to generate such a game, but being lazy (and not knowing too much about IA) I offloaded prompt generation to GPT:
Generate a good prompt for copilot AI in Visual Code so it generates code for the snake game. Snake game can be the simplest possible terminal based game on a small field.The output was pretty reasonable prompt, which I could have written (but, hey, that takes time). The only thing I updated in the prompt was the very last line to keep track of the score of the game:
# Write a simple snake game in Python that runs in the terminal.
# Requirements:
# - Keep the game as simple as possible.
# - Use a small fixed grid (e.g., 10x10).
# - The snake moves automatically in the last chosen direction.
# - Use WASD keys for movement (no fancy key handling needed, blocking input is fine).
# - Place food randomly; eating food makes the snake longer.
# - The game ends if the snake runs into itself or the walls.
# - Print the field after each move using simple ASCII characters:
# - "." for empty space
# - "O" for snake body
# - "X" for snake head
# - "*" for food
# - Keep the code in a single file, no external libraries beyond Python standard library.
# - Keep it short and readable.
# - Keep the score of the game. The score equals the total number of food eaten.The generated code (with gpt-4o) was 73 lines of code and I could play the game in the terminal: https://github.com/andriybuday/snake-ia/blob/main/snake_game.py
Step 2: Generating AI that learns to play and watching it play
Again, prompt to get the prompt:
Now we need another prompt. This time we want to use pytorch and will be building a simple 2 hidden layers neural network with reinforcement learning. Use large punishment for loosing the game and small rewards for each eaten food. We want to achieve quick learning without too many iterations.
The prompt it generated this time was much more extensive. Here are all of the prompts: https://github.com/andriybuday/snake-ia/blob/main/README.md I then fed that prompt to both GPT-4o and Claude.
Claude generated a much better AI. GPT generated something that couldn’t even get more than one food score, which Claude was in the territory of 10-20 score. Note, that max theoretical score on 10×10 is 99. You can see above a gif showing last few epochs of training and game play of the Claude version.
The code for this version: https://github.com/andriybuday/snake-ia/blob/main/snake_game_ai_claude.py
Step 3: Improving AI so it reaches better scores
Ok, so what can be done to make this reach better scores? I asked GPT to recommend some improvements. It gave me general recommendations out of which I created a prompt for prompt:
Generate prompt I can give to Claude to improve performance of the Snake AI, potentially with these improvements: Change head to Dueling DQN, Add Double DQN target selection, Add PER (proportional, α=0.6, β anneal 0.4→1.0), Add 3-step returns, Add distance-delta shaping + starvation cap.To be honest, at this point I don’t know if these improvements make sense or not, but I took the generated prompt and fed it to Claude. And what I got was broken code, which crashes on the “IndexError: Dimension out of range”. I was hoping to run into something like this. Finally. Now I can probably debug the problem and try to find where we are running out of range, but no, I’m sharing the error and stack trace to Claude again. It was able to fix it BUT things got worse, the snake would run into infinite loops.
Turns out generated “upgraded” version is much worse. So I decided to take a different path and get back to simple first version and see what can be updated. The only things I did were increasing training time (# episodes), allowing for more steps for training, and slightly decreasing time penalty. This is the change: https://github.com/andriybuday/snake-ia/commit/796ad35924700dcb73ac6aaecf8df39ec8069940
With the above changes the situation was much better but still not ideal.
Conclusion
Sorry for the abrupt ending, but I don’t really have time to fine-tune the generated NN or create new models to achieve the best results. The purpose here was to play and see what we can get really quickly. Also another purpose of this post is to show that people, like me in this case, who just do Vibe Coding without knowing underlaying fundamentals cannot really achieve best results really quickly. Happy Vibe Coding!
Try it yourself:
git clone https://github.com/andriybuday/snake-ia.git
cd snake-ia
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
python snake_game_ai_claude.py
My Framework for Dealing with Ambiguity
September 7, 2025 Opinion, Personal No comments
Dealing with ambiguity is one of the key skills sought after in software engineers. The more senior you are the more you are expected to know how to handle it. But even outside of work we have to make decisions in uncertain situations. In this post I would like to share some thoughts on this go over existing frameworks, and synthesize a new framework.
Before we dive in, so that you know, I don’t like uncertainty and ambiguity that much and would like to briefly revisit a point from a previous post, that a person has to be a psychopath not to worry about uncertainties at all, but at the same time uncertainty is a core part of our lives and we should learn to embrace it.

Baselining
Let’s first expand a bit, mainly because “dealing with ambiguity” has some ambiguity to it. The word itself could mean uncertainty but it can also mean something bearing multiple meanings. Multiple meanings to the same definition is a more strict meaning of the word, but:
- If you interpret it as purely ambiguity (multiple interpretations), you might miss the fact that your company also expects you to handle incomplete, uncertain futures.
- If you interpret it as just uncertainty, you might miss the expectation that you actively clarify, simplify, and drive alignment when things are already vaguely defined.
So for the sake of this post it is both: uncertainty and multiple interpretations.
Expanding
What are some existing frameworks and approaches for dealing with ambiguity?
- Cone of Uncertainty
- What: Early estimates are highly uncertain but converge as more information is discovered.
- Personal take: I really like to point to this one whenever someone isn’t too sure about a project. I don’t only frame it as estimates but overall uncertainty and ambiguity reduces as the time passes. This also helps me put any project into perspective and
- Double Diamond
- What: The Double Diamond is a structured approach to tackle design or creative challenges in four phases:
- Discover/Research → insight into the problem (diverging)
- Define/Synthesis → the area to focus upon (converging)
- Develop/Ideation → potential solutions (diverging)
- Deliver/Implementation → solutions that work (converging)
- Personal take: Honestly, the double-diamond framework isn’t something I knew about before writing this post, but I could see how it is similar to what I’m used to doing anyways whenever designing a system at work or even approaching something creating, like writing a blog post.
- What: The Double Diamond is a structured approach to tackle design or creative challenges in four phases:
- OODA: Observe–Orient–Decide–Act
- What: Borrowed from the military framework for fast-moving, changing situations and decision making. This is particularly useful for competitive environments.
- Personal take: while software engineering isn’t so dynamic and competitive, some elements of this framework are useful, especially quick re-orientation based on observations.
- Cynefin framework
- What: Cynefin offers four decision-making contexts or “domains”:
- Obvious (Clear): Cause–effect obvious → apply best practices.
- Complicated: Cause–effect requires expertise → apply good practices.
- Complex: Cause–effect only clear in hindsight → probe, sense, respond.
- Chaotic: No cause–effect → act to stabilize, then respond.
- Confusion (Disorder): Domain unclear → break down into parts.
- What: Cynefin offers four decision-making contexts or “domains”:
- First Principles Thinking
- What: When ambiguity comes from assumptions, noise, or convention, break down a problem to its fundamental truths, then build reasoning from the ground up.
- Personal take: this seems to be the best approach when you observe that people talk about the same thing but in different ways or they use same words but mean different things.
- Lean / Agile
- What: Build → Measure → Learn loop to reduce uncertainty with fast experiments.
- Personal take: In a way agile was specifically created to deal with ambiguity by prioritizing adaptability over too much upfront planning (waterfall). I personally was a big proponent of agile methodologies. Sometimes there are too many rituals associated with these methodologies, but otherwise it’s great.
- Others…
Map -> Reduce by Priority
Can we synthetize these approaches into something that works specifically for us, software engineers? Maybe, yes, maybe not. What I mean is that sometimes one particular tool works best in one situation but doesn’t work too well in another. But regardless, I think there are enough similarities and here is my attempt, based on my experience:
- Step 1: Baseline: quickly document known knowns, known unknowns, and range for unknown unknowns. Potentially something like Cynefin categorization can be used here, but I normally just go with a format that best works for a given situation.
- Step 2: Expand: Go on a quest to discover and collect even more of the unknown. Yeah, this step is actually hard to do, because instead of formulating some hypothesis or making assumptions this asks to seek more uncertainty. Practically, most of the time, this boils down to talking to more people and asking them to give more points of contact to talk to. Obviously, the more people you talk to the more perspectives you get. I think this overlaps with “Discover/Research” from the double-diamond or “observe” from OODA.
- Step 3: Map -> Reduce by Priority: Analyze information collected in the “Expand” step, identify key similarities, and group where possible, thus reducing the number of possible interpretations and meanings. One important thing could be to see which of the collected artifacts might have the outsized end result on the project. For example, an increase in latency of a service is uncertain, but it simply could be a complete blocker for the project, so this uncertainty should be prioritized. No point in reducing uncertainty elsewhere if this one shows the entire idea is no-go. There might be multiple tracks to reduce uncertainty here and this can be parallelized (similarly to map-reduce). This roughly maps to “decide->act” from OODA or “Define”/”Deliver” phases from double-diamond, or “measure” phase from Agile / Lean.
- Step 4: Synthesize and Iterate: Some of the most critical uncertainties and ambiguity was reduced in the previous step, so now it is a good time to converge on a new revised state of the things and suggest a course of action based on gained knowledge. Practically this means answering all of the questions about most critical unknowns, and how remaining unknowns will be mitigated.
Synthesize and Iterate
The Framework:
- Baseline: List what’s known and unknown (use Cynefin or a simple format).
- Expand: Actively seek more perspectives and data to surface hidden unknowns.
- Map and Prioritize: Group findings, reduce interpretations, and tackle the highest-impact uncertainties first.
- Synthesize and Iterate: Converge on a clearer picture, decide actions, and repeat as needed.
Conclusion
In fact, I used this same framework while writing this blog post. Baselining what I knew, expanding with research, mapping frameworks, and finally synthesizing a new approach. Ambiguity is unavoidable in code, projects, and life. I’d love to hear how you personally deal with ambiguity, are you using any structure or framework for it?
How I Finally Made Early Mornings Work for Me (After 20 Years of Failing)
August 31, 2025 Opinion, Personal 2 comments
I found a “cheat code” for my productivity, which is getting about 3 hours of deeply focused work before any meetings.

Yes, it does sound like a cliche to say “wake up at 5AM and get most work done before others wake up”. But for most of my life this was pure fantasy. In the past during early AM I used to be a brainless zombie. More often than not I would snooze all of my alarms (like seven times, not joking). Whenever I tried to go to bed early I would get laughed at and it didn’t actually work.
Sometimes I would get these 3 hours of focused work in the very late afternoon once meetings are over or at night. This worked, but the consistency was missing. The problem with evenings is that life has its own plans and oftentimes you get some commitments in the evenings. Super early mornings, on the other hand, are different. There are no meetings, no interruptions, no notifications, no nothing. You are in full control of your time.
Here is what finally worked for me (and no, I’m not selling anything):
- Enough sleep. The single most important factor was to get enough sleep the night before. My needs for sleep change depending on the amount of physical activity and the quality of sleep the previous night. I had to learn to adjust. I’m using Garmin “sleep coach” and if it says to sleep +40min this is what I target to go to bed earlier. I found that, for instance, a super-intensive kickboxing class increases my needs by about 50 minutes. Not getting enough sleep wrecks the next day.
- Autopilot morning. I removed all of the friction from early morning routines. I prepare all my clothes, work stuff, keys, everything the night before. Everything is in the exact same spot every morning. When I wake I don’t have to think. I just go on fast autopilot and 25 minutes from wake-up (no joke) I’m in the office sipping my reward: espresso coffee freshly made by myself in the office. By now it is a bit of a ritual for me.
- Commitments. I keep running accountability growth challenges with friends. That additional accountability layer keeps me honest.
The results?
The biggest change isn’t just productivity but it’s how I feel.
When I used to start my day around 10AM I felt agitated. I’d go through early meetings half-asleep while knowing there was real work piling up in the background.
Instead now, as a huge contrast, I enter the day having already accomplished something of substance. The other day, before the first 10AM meeting, I published 3 code changes and wrote 2 documents. I don’t always do this much early on but this shows the scale of the difference those few early hours make. I enter meetings calmer, more confident, and less reactive.
Conclusion
I failed for 20 years before I was able to do this. I didn’t want to write this blog post until I had at least half a year of consistent early mornings, because that’s the hard part. For me, waking up early stopped being a punishment and became a secret weapon. I’m actually looking forward to working hard and focused early when no one can distract me. If you are struggling with something, don’t give up, try again. It might take time, but eventually it can work out for you too.
I’m curious what’s your cheat code for creating time for deep work?
On AI and Adaptability: AI is an asteroid and your software engineering job is a dinosaur
August 24, 2025 AI 2 comments

AI is the asteroid. Your job is the dinosaur. The question is: will your career evolve like mammals, or go extinct like T-Rex? I’m not saying that software engineering jobs will disappear, I am saying they will transform from their current form. Dinosaur jobs are things like writing boilerplate CRUD. New mammal jobs are things like designing AI-integrated systems. There is a lot in between that evolves.
Tech companies are now piloting AI powered interviews where you have to build something using AI during the interview. Are you ready for such an interview? I’m definitely not ready. Would you be able to survive this change next time you are on the lookout for the new job?
These days, with AI, being productive as a software engineer is not the same. A bit of a challenge with AI tools is that they are all new and rapidly evolving. One day, writing good prompts is good skill, next day building AI agents to do the job for you is the next thing, one model is good at this, another one is good at that. The amount of things available is also quite overwhelming.
I remember at one point in my career I felt I got really good at using Visual Studio with Resharper, so good that it actually felt like a significant differentiator in my speed compared to others. Then when I had to switch to other tools/tech (frontend, java, aws, other IDEs, etc) it felt unnatural and was leveling the playing field or placing me at disadvantage compared to people who already knew how to use the other tools. At the same time, the more I had to learn new tools the easier it was to switch the next time.
Adaptability is probably one of the best skills to work on during this rapid evolution in tech. We simply cannot afford to ignore AI, that would be the biggest career mistake you could make right now.
And to make one more point very clear: I believe that software engineering requires strong fundamental knowledge that doesn’t change: understanding of how computers work and interact with each other, understanding of how software runs, algorithms. There will always be a need to figure out how to translate business needs into these fundamental concepts, it is just that the translation tooling landscape is changing and we need to get good at them.
The asteroid has already hit. Your career’s survival depends on adaptability and fundamentals. Learn fast, stay curious, and don’t bet your career on yesterday’s tools. I’m writing this as much for myself as for you. I need to step up a lot.
What is a new AI tool/concept you learned last month?
(for me it was about the architecture of AI agents, incl. MCP protocol)
The Promotion Formula: My Take
August 10, 2025 Career, Success 2 comments
Promotions in tech companies aren’t random, but they’re not entirely deterministic either. Here’s my humble attempt on a generic ‘mathematical’ formula I think makes sense.

Disclaimer: In no way this blog post represents the official position of the companies I worked for in the past or now. While I will try to make this generic, I’m definitely biased by my past experiences, plus my visibility is definitely not that of a VP level, so take this with as big of a grain of salt as you can imagine.
Background
In my career I had 5 promotions, 3 before FAANG and 2 at FAANG. I helped some of the engineers on my past teams get promoted, mentored a few people outside my org/team, and participated in the promo committee.
I’m definitely not in the high percentile in terms of how far I got with my promotions. There are people who are many levels higher, got there quicker, and didn’t write a word about it. Some think chasing titles is pointless or even toxic. Others say real engineers should just build what they believe in or launch their own startups. I’m writing because it is my thing. I had my path, and you and others have different paths, this is just how life works. So with that healthy dose of self-awareness and some humility, let’s develop a formula for success:
What is the ‘formula’ for promotion?
Unless you’re in a chaotic startup or very small company, promotions usually follow a structured process. The criteria often include your performance, leadership skills, and feedback from others. If I were to boil it down into a formula, it would look like this:
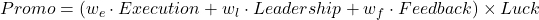
Where:
- Promotion: Readiness score where < 1.0 means not ready, > 1.0 means ready.
- Execution: Quantifies direct work (impact, quality, next-level scope); 1.0 = fully executing at next level, 0.8 = close.
- Leadership: Measures ownership, influence, and decision-making, partly quantifiable.
- Feedback: Continuous feedback and visibility through reviews, leadership exposure, and collaboration; hard to quantify but significant.
- Luck: Multiplier (0.5–1.5) that can amplify or dampen other factors; includes final promo packet outcome as a last-moment swing factor.
- Weights: Company and level-specific emphasis on factors (sum to 1); e.g., Meta/Amazon may set we≈0.5, a small company may set wf≈0.7.
Now, lets go over each of these with more details and my thoughts on how you can increase each one of them:
Execution
Most of the time this is the most significant part to promotion, especially at entry and mid levels. It’s the quantification of impact, quality of work, delivering results. Here are some very specific things you can do:
- Basics: Do your job and do it well.
- Quantification: Measure the impact of your work before, during, and after delivery. Even maintenance work can be framed in terms of what would happen if it weren’t done.
- Projects: Focus on high-impact, high-ROI projects. If your project doesn’t seem impactful, either (1) quantify ROI properly, (2) find ways to increase the scope/impact, or (3) if it’s truly low-value, align with stakeholders to drop it and move on.
- Quality: Show engineering or operational excellence, not just speed. This is because cutting corners may get quick wins, but over time they hurt your credibility.
- Scope: read the description of the next level and create mini-gap analysis if the scope of what you are working on is going to fill-in those gaps.
There are many other things to consider here, so see what you still need to do to tick all the marks of the next level of execution. That having said, strong execution gets you good hard data, but without leadership and visibility, it may not get you promoted.
Leadership
If you just joined the company as a fresh grad, not much leadership is expected of you, your Wl coefficient in the formula above will be really small (~0.1) and the higher you go the larger this coefficient is going to be. Companies have their approaches to how to measure this, for instance Amazon has 14 leadership principles, Meta has “Direction” and “People” axis, Google and other companies have their own things.
I will say something controversial, and hard to accept, but IMO a lot of your leadership potential is already backed in your personality at adulthood. I am not saying it is not possible to grow as a leader and improve, what I’m saying is that for some people it comes more naturally because they are more extroverted, confident, and more charismatic. To be clear: if you actively work on improving your leadership skills you will get much further than someone who has better prerequisites but isn’t trying to improve.
Usually, if you are going for promo, you would need to tick some boxes, depending on the framing you company is using.
- Influence. Have examples of influencing others. While influencing with authority is easy, for promotion you would need to show how you influenced peers or your leadership by presenting solid data, writing crisp documents, showing prototypes, telling convincing stories. If you have examples of where you influenced the roadmap at your skip level that would stand out. Trying to influence overly hard can backfire as people could perceive this as you being pushy, so come to them with clarity and data.
- Communication. Communicate clearly, timely, upwards. While this makes sense it is often a lot harder that it sounds. I’ve seen many solid technical engineers that really really struggle with communication. Sometimes the reason could just be English as a second language, but more often than not it is all the cluttering, odd structuring, that has nothing to do with the language proficiency.
- Strategic thinking: Strategize about your area of work, even if you are more junior show that you have given thought to how things should pan out in long term and if you are senior the expectation would be to create scope and solve ambiguous problems, or even find problems where others don’t even see them (yet).
- Trust: Build that trust because it takes time. Higher level leaders often operate on trust they have in their senior engineers.
- Dealing with ambiguity. The more straightforward the task is the less easier it is to automate and the more unvalued it is. At the age of AI, more and more of clearly defined tasks are going to be automated, so you bring value by being human and being able to deal with all of the missing pieces, unclarity and other things of that sort.
- Leadership gaps: Identify any company specific leadership requirements they might have, these can include: conflict resolutions, raising the bar, mentoring, etc.
At the end of the day someone will have to provide feedback about your work.
Feedback / Visibility
By feedback in my formula I didn’t just mean final feedback you get on your promo package but more of continuous things that includes manager/peer reviews, visibility with leadership, work with other people, this is hardly quantifiable in numbers but does play a significant role in the promotion as this builds that perception around you.
- Manager: Work with your manager to have a complete alignment on expectations and check-in regularly on your own initiative.
- Peers, cross-org, and your reportees: Just don’t be a jerk to others, express gratitude, be helpful. Doesn’t sound like much, but these things are appreciated.
- Higher leadership. Create a name for the project association in the minds of your leadership. When promo time comes you are not a simple spreadsheet line to them.
- Deliver visible wins: demo your work, share launch emails, and post in relevant channels so more people see the impact.
- Credit: Credit the team in public updates, but make your own role clear in 1:1s with decision-makers. Never take someone’s credit but be clear if you did contribute so that your credit is not misassigned.
Now, you might have all the great execution, leadership and visibility, there is one last piece that might override it all and it is the effect of luck.
Luck
One purely deterministic and cold-blooded view is that you are worth exactly what you are worth, meaning that if you somehow think you deserve a higher level this is simply wrong as you were not able to determine what it takes to get that what you want and therefore you don’t deserve it. Big companies have a data-driven approach to promotions, so if you have the data for the next level you would undeniably get it.
I do not buy this idealistic view and that’s why I introduced the Luck multiplier to my formula. It is a multiplier rather than an additive term, because it can significantly boost or dampen the effect of your other factors – you can execute and lead perfectly but still be blocked by bad timing, or get promoted earlier due to being in a high-visibility project at the right moment and because your org has big promo budget that time. You might have worked on a project that suddenly started making millions/billions of dollars growing and riding everyone’s careers with it or you might have worked on a failed project and got laid off.
So if there is so much you cannot control, do you just give up? Well, maybe, work on slightly improving your chances:
- Preparation. Deliberately invest learning and self-growth. While it might not give you that immediate promo, it can position you well in the future.
- Openness to opportunities. Do not ignore opportunities when you see them, evaluate them and act on them. It has some risk, yes, but as one of my first mentors once said “Never moving fish is a dead fish”.
Weights
Weights used in my formula are reflecting your company’s emphasis on each factor for a given level (they sum to 1 for normalization), for example companies like Meta or Amazon can make huge emphasis on Execution, making that We close to 0.5, while your small company really trusts what the others say about you so Wf is 0.7. At a very senior level your Wl becomes a much larger contributor.
Once you know your scores and weights, here’s how to move them.
Strategy and Tactical Plan
Here is the advice I give people when they ask me about promotion and it consists of two big steps:
- Career Strategy: Write down a strategy for your career. A long term one. One that describes what the hell you want to achieve in your career in 1, 2, 5 years. You don’t have to share it with anyone, but it will help you build clarity for yourself. Go, do it right now, create a Google doc, write some raw disconnected sentences, and expand to make it more crisp over time. I happen to be at Meta because it was part of my Career Strategy.
- Tactical Plan: Find a promo document template and start filling it in, even if your promotion is 1 year away.
- Start with a target date for your promotion, work out what makes sense, align that with your manager. If you are not getting definite ‘yes’ from the manager it is the feedback you are too aggressive and you might not see something.
- Identify any missing gaps, what’s needed to get you from A to B, start on your own based on your company’s framework and template, involve your manager, and gather feedback.
- Identify any blind spots, as usually there will be things you don’t know about, your manager might not be directly telling you. A mentor can help you get that outsider perspective.
Conclusion
Luck is outside your control, but readiness isn’t. Don’t judge others purely by their title, success of their project or generally where they are in their life, everyone fights their own demons and battles, you just don’t know. The best shot you have at a promotion is to consistently operate at the next level in execution, leadership, and visibility. In this post I’ve shared my formula:
Promo = (Execution + Leadership + Feedback) * Luck
If you work deliberately on each part, you shift the odds in your favor. Hopefully, what I’ve shared here gives you a clearer map for getting to your next level.
Is AI Redefining Software Craftsmanship?
August 2, 2025 AI, RandomThoughts No comments

Let’s debate over the question: Is AI redefining what software craftsmanship is?
To answer this question we must first define and expand on what software craftsmanship is.
Software Craftsmanship (SC) can be defined as a mindset and approach to creating software that puts emphasis on quality, elegance, adherence to best practices, and continuous skill development.
Many ideas behind SC are shaped by books, like “Clean Code”, “The Pragmatic Programmer”, “Code Complete” and more. I’ve personally read these books in the past and have considered myself to be sort of a Software Craftsman, mainly because of taking pride in producing high quality code.
Let’s explore the “Yes” argument with an example. In my 2012 blog post “100% code coverage – real and good!” I argued that striving for absolute test coverage is not only realistic but professionally responsible saying it pays off in the long run. Recently, I worked on logic that needed new unit tests. AI generated over 100 tests for me, covering all the edge cases. It saved me tons of hours of work. I now treat these tests as a black-box safety harness. If I change the logic and introduce a bug, I expect one of them to fail. If I need to refactor heavily or modify API signatures, I simply ask AI to regenerate the tests. I no longer care if helper methods in the tests are extracted or follow perfect conventions because that’s now a solved problem. So, yes, AI is redefining what a software craftsman does.
Let’s explore the “No” argument. A colleague of mine, gave this example: in the privacy space, AI can generate some “good” code, but it might not go as far as to care about whether using a raw pointer in C++ code is higher risk because of the privacy context, and if you are not a SC you would simply not pay attention to that part and let it slip, similarly how I would not care about that extracted method in unit tests. So the argument goes, that AI cannot truly produce SC’s level of quality. Playing a bit of devil’s advocate, I think, AI will actually get good at caring about raw pointers, extracted methods, and other things like that. Perhaps we’re not replacing craftsmanship but rather we’re just shifting it to a higher level of abstraction.
To finish off, there was a time when people wrote in absolute binary (01110110) using absolute machine addresses and many programmers of that time resisted using symbolic approaches (like FORTRAN). The adoption by professionals was slow, because, hey, that’s “not true programming”. To replace another popular statement:
Software craftsmen won’t be replaced by AI, but those who use AI will replace those who don’t.
P.S. The idea for this post originated from a random conversation over dinner with a random co-worker I’ve never met before.
